High Responsiveness for Group Editing CRDTs 요약
“High Responsiveness for Group Editing CRDTs.” 읽으면서 정리한 내용
요약
공동 편집에는 빠른 응답성을 위해서 OT, CRDT와 같은 Optimistic Replication 알고리즘이 사용되고 있음. 보통 CRDT가 downstream(원격) 오퍼레이션을 처리할 때 빠름(CRDT: 지수 시간, OT: 제곱 시간). 하지만 CRDT는 upstream(로컬) 오퍼레이션 처리시 선형 시간 복잡도라서 응답성이 느림
이 논문은 CRDT의 앞 부분에 “identifier data structure”라는 보조 데이터 타입을 제공해서 upstream 오퍼레이션 처리를 개선하는 방법을 제안함. identifier data structure는 동기화나 복제를 필요로 하지 않음.
identifier data structure를 블록 단위 저장 접근 방식과 함께 사용하면 upstream 실행을 상당히 개선할 수 있음(무시해도 되는 정도의 메모리, 네트워크, downstream 실행 시간이 추가됨).
1. 도입
Optimistic Replication
공동 편집에는 응답성이 매우 중요하므로 네트워크 지연이나 문서의 락에 영향을 받지 않도록 모든 유저는 자신의 디바이스에 편집하는 문서의 리플리카를 갖고 있는데, 이를 Optimistic Replication이라 부른다. 사용자의 편집 오퍼레이션은 로컬 리플리카에 먼저 반영되고 원격에 있는 다른 사용자의 리플리카에 전송된다.
- upstream 실행: 로컬 오퍼레이션을 처리
- downstream 실행: 다른 사용자가 전송한 원격 오퍼레이션을 처리, 임의의 동시 편집도 해결 해야함
OT
OT는 upstream의 빠른 응답성으로 공동 편집에 사용되었지만, 각 리플리카의 히스토리를 재정렬하고 오퍼레이션을 변환해야 하므로 downstream의 처리 속도가 특히 분산 환경에서 매우 느림(O(N^2k), N: 오퍼레이션의 수, k: 리플리카 수).
CRDT
이를 해결하기 위해서 CRDT가 도입되었고 교환 법칙(commutative)의 오퍼레이션을 사용해서 downstream 실행시 리플리카의 일관성을 위해서 오퍼레이션을 별도로 변환하거나 정렬할 필요가 없다. 하지만 보통 CRDT 유형의 알고리즘은 upstream 처리시에 고유한 identifier를 생성하거나 조회되어야 하므로 upstream 처리가 느린 경향이 있다.
Block-wise approach
이를 개선하는 첫 제안은 문자를 하나하나 저장하지 않고 블록 단위로 저장하는 것이었는데, 고유한 identifier를 갖는 요소들이 줄어드므로 선형적인 처리시 유리했고 각 요소가 고유한 identifier와 같이 메타데이터를 갖고 있었으므로 메모리도 작게 사용했다. 하지만 블록으로 연결했다고 하지만 여전히 선형 시간의 복잡도를 갖고 있다.
Identifier data structure
이 논문은 upstream 처리 시간을 상당히 개선할 수 있으며 대부분의 CRDT 알고리즘에 적용할 수 있는 Identifier data structure를 제안하는데, 이는 각 피어(peer)가 자신의 독립적인 구조를 갖고 있으므로 동기화 할 필요가 없고 동시성 이슈를 고려할 필요가 없다. Identifier data structure를 도입하면 본래의 알고리즘에 비해서 네트워크, 메모리 그리고 downstream 처리에 약간의 간접 비용이 있지만 무시할 정도다.
2. 배경, 관련 CRDT들
2.3.1 WOOT
WOOT에서 identifier는 피어의 아이디와 삽입시 좌우측의 두 앨리먼트에 대한 링크로 구성된다. 결정론적 알고리즘으로 동일한 구역에서 요소들이 동일한 순서를 갖지만, 매우 복잡하고 처리 비용이 크다. 각 요소의 위치가 이웃 요소와 관계에 의해 결정되므로 완전히 삭제하기가 어려워서 tombstone을 사용한다. WOOT의 최적화 버전이 제안되었지만, downstream 처리 속도만 개선되었다.
2.3.2 TreeDoc
요소의 비균형 이진 탐색트리로 요소의 identifier는 트리에서의 Path이다. 이진탐색이 가능하지만, 트리가 비균형이므로 문서의 끝에 계속해서 텍스트를 입력할 경우, 균형이 깨져서 고비용이 발생한다. 모든 피어에서 트리의 모양이 동일하며, 균형을 맞추려면 모든 피어를 동기화 해야하므로 균형을 잡는 것은 불가능하다. tombstone을 사용하지만, 특정 조건에서 제거가 가능하다.
2.3.3 Logoot
어휘 순서를 사용해서 문서의 요소의 순서를 잡는다. identifier는 3개의 정수형 튜플(1: 우선순위, 2: Upstream 피어 ID, 3: Upstream 논리 시계)의 리스트다. identifier는 배열에 저장되며, 새로운 요소 삽입을 위해서는 배열의 shift가 발생한다. (생략)
2.3.4 LogootSplit
Logoot의 블록버전 (생략)
2.3.5 RGA
RGA는 문서에서 모든 요소는 특정 요소 뒤에 추가된다는 점을 이용한다. RGA 자료구조는 링크드 리스트로 각 요소는 내용과 다음 요소의 링크, tombstone으로 구성된다. identifier는 피어 ID, sum(삽입중 upstream 벡터 시계의 합)으로 구성된다. identifier의 순서는 피어 ID와 sum으로 판단된다.
2.4 요약
빠른 반응성을 위해서 upstream에서 로그 시간 복잡도가 필요하지만, 이전 알고리즘은 이를 제공하지 못했다.
- OT는 TTF tombstone
- RGA와 WOOT는 tombstone
- Logoot는 자체 배열을 shift해야 했으며, LogootSplit은 identifier를 관리해야 함
- Treedoc은 불균형 트리를 탐색해야 함
- Block 접근방식은 블록 크기에 의존적
사용성에 직결되는 upstream 실행시간은 매우 중요했다. RGA는 downstream 실행이 매우 우수했다.
3. Identifier 자료구조
이 논문에서는 각 피어마다 본 알고리즘에 영향도가 작은 Identifier 자료구조를 제안한다. upstream 실행시간을 로그시간으로 수행한다.
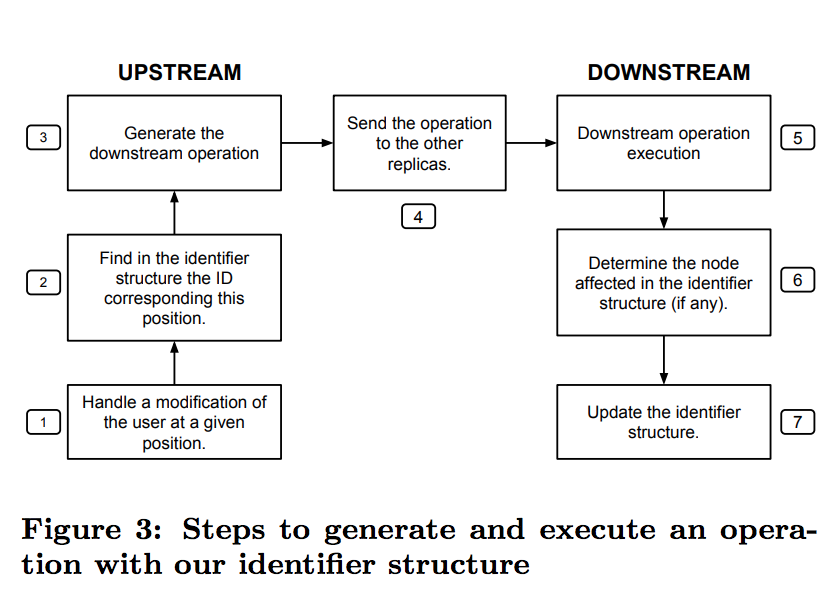
- 스텝 1: 사용자 액션
- 스텝 2: 사용자의 액션으로부터 Identifier 자료구조를 사용해서 Node를 조회
- 스텝 3-5: 본 알고리즘과 동일한 복제 과정
- 스텝 6-7: 원격 오퍼레이션을 받아서 로컬 Identifier 자료구조를 업데이트
idNode는 Node를 참조를 갖고 있고 반대로 Node는 idNode의 참조를 갖고 있다.
3.1 CRDT identifier를 조회하기
RGA와 WOOT, LogooSplit에서 문서의 노드를 조회할 때 시작작 노드부터 찾는 위치의 노드를 만날때 까지 선형탐색 한다(O(N)).
Identifier 자료구조는 사용자의 수정 위치를 입력받아서 CRDT identifier를 빠르게 찾는 역할을 한다. Identifier가 순서를 갖고 있다면, Identifier 자료구조는 스킵 리스트와 같은 SortedMap이거나 혹은 weighted binary tree가 될 수 있다.
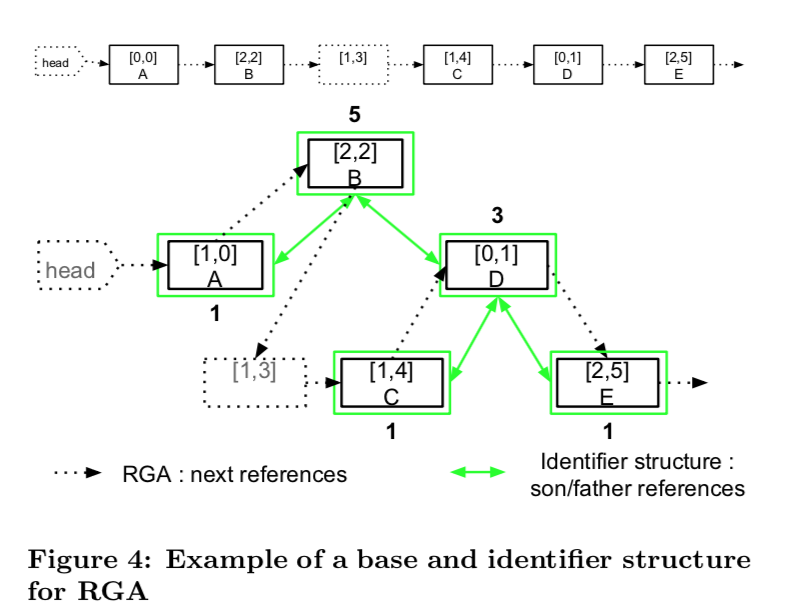
RGA에 identifier 자료구조(weighted tree)를 적용할 경우
- idNode: 레퍼런스(left child, right child, parent)와 weight(하위 트리의 전체 크기), RGA 노드의 참조
- RGA Node: 기본 (identifier, 내용, next 레퍼런스, tombstone)에 idNode의 참조 추가

사용자의 위치(pos)로 부터 특정 Node를 찾을 때, weight를 비교하면서 identifier를 검색
3.2 downstream 에서 identifier 자료구조 업데이트하기
RGA에서 삽입 오퍼레이션에는 대상 노드의 identifier와 새로운 값이 포함되어 있다. 이 논문에서는 downstream에서 RGA의 기본 알고리즘으로 대상 노드가 찾아진 뒤에 identifier 자료구조를 업데이트 한다.
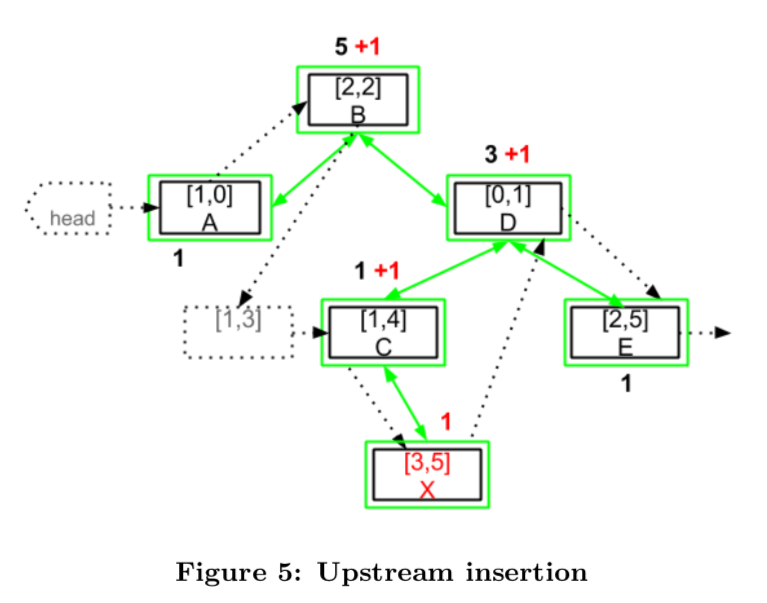
Identifier 자료구조는 tombstone 노드를 포함하지 않으므로 deletion에는 아무처리를 하지 않고 insertion의 경우 아래와 같은 로직을 수행한다.
(XXX: 삭제시에도 대상 idNode를 삭제하고 weight를 업데이트 해야한다).

3.3 identifier 자료구조 Logoot에 적용
(생략)
4. RGATreeSplit: RGA + 블록화 + identifier 자료구조
논문에서는 RGA가 downstream 실행에 가장 효율적인 알고리즘이고 블록 알고리즘을 적용하면, upstream과 downstream 실행을 모두 개선하므로 identifier 자료구조를 포함한 RGATreeSplit을 제안함.
4.1 block-wise RGA: RGA + 블록화
이 논문에서는 block-wise RGA에는 “W. Yu. A string-wise CRDT for group editing.”에서 제안한 split과 offset 개념을 추가했다.
각 노드는 다음 속성을 갖고 있다.
- content: 메모리 효율을 위해서 tombstone화 되면, 제거 될 수 있다.
- identifier: 기존 RGA identifier
- nextLink: 기존 RGA의 다음 노드의 참조
- offset: 사용자가 삽입한 본 위치
- splitLink: split시에 다음 노드의 참조
- length: 본문의 크기
offset x에 있는 노드를 pos로 split하면, 첫 노드의 offset은 x, 두 번째 노드의 offset은 x + pos
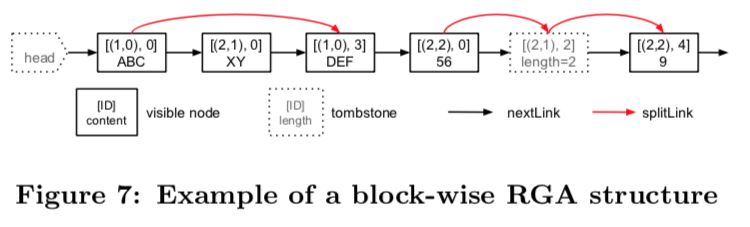
- 리플리카 1에서 사용자가 “ABCDEF” 삽입, identifier 는 [[1, 0], 0]
- 리플리카 2에서 “ABCDEF”를 전달받고 사용자가 “XY”를 pos 3에 추가, identifier 는 [[2, 1], 0] “ABCDEF” 블록은 “ABC”, identifier [[1, 0], 0]와 “DEF”, identifier [[1, 0], 3]로 쪼개짐
- 리플리카 2에서 “56789”를 마지막에 삽입 identifier는 [[2, 2], 0]
- 리플리카 2에서 “78” 삭제 “56789” 블록은 (“56” identifier [[2,2],0])과 (tombstone, identifier [[2, 2], 2])그리고 (“9” identifier [[2, 2], 4])로 쪼개짐.
FINDOFFSET: identifier와 offset을 입력받아서 특정 node를 찾는 함수

splitLink는 identifier와 offset을 기준으로 특정 노드를 찾을 때, 성능을 위해 사용함.
4.2 RGATreeSplit의 identifier 자료구조
기본적으로 3절과 비슷하지만, 몇 가지 차이가 있음
첫째. Identifier 자료구조와 findPosInIdentifierTree 함수의 weight에 블록 content의 크기를 반영한다.

둘째. 오퍼레이션 반영시에 대상 노드를 분할해야 한다.
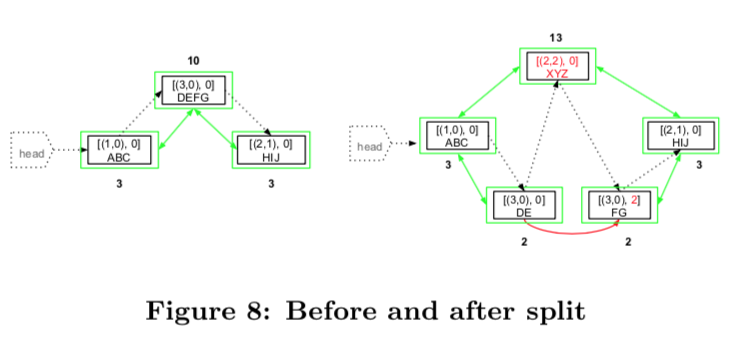
삽입 오퍼레이션은 3개(2개: 기존 노드 split, 1개: 새로운 노드)의 새로운 블록을 만들어야한다. 간단한 방법은 기존 노드를 새로운 노드의 값으로 치환하고 새로운 노드 좌측(insertBefore))과 우측(insertAfter)에 2개의 split 노드를 삽입하는 방법이다.
5. 평가와 실험
5.1 구현
3절의 identifier 자료구조로 Binary weighted tree를 도입하는 경우 balanced 혹은 unbalanced(주기적 balance)의 두가지 구현 방식이 있다.
- RGA, Logoot: TreeList(AVL 기반), 단순한 구현위해 downstream에도 별도 hashtable 없이 TreeList로 찾음
- RGATreeSplit: weighted unbalanced binary tree(주기적으로 리밸런싱 수행), 리밸런싱 처리도중 응답성이 떨어질 수 있으므로 사용자가 편집을 잠시 쉬는 동안 실행 권장(실험용 구현이라 그냥 이렇게 함…)
5.2 실험
- 노드: Intel Xeon X3440 processors (2.53GHz), 16GB of RAM, Wheezy-x64-big-1.0 operating systems on Debian. 싱글 쓰레드.
- 입력: 사용자 수정 오퍼레이션을 무작위로 생성했으며, 모든 알고리즘에 대해 동일한 세트 사용
- 오퍼레이션의 수와 순서가 서로 다른 여섯 개의 실험(5000, 10000, 15000, 20000, 30000 및 40000개)
5.3 싱글 엘리먼트 시리즈
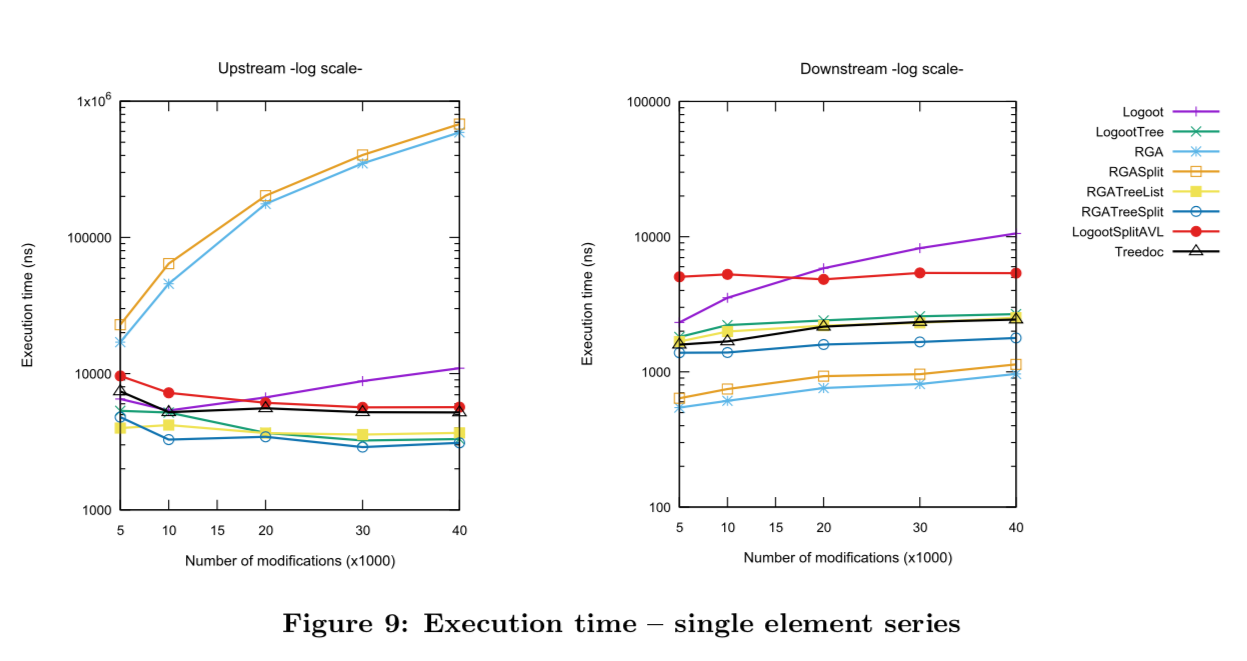
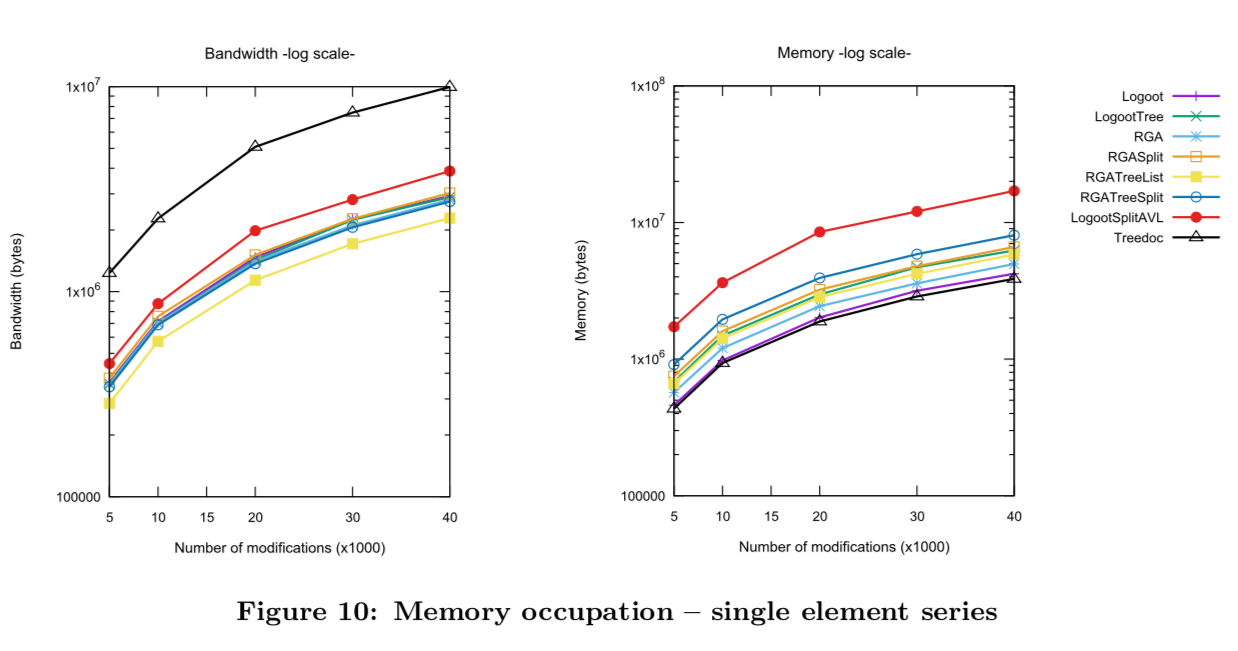
- 입력 오퍼레이션 특징: 한 요소에만 영향을 주는 수정
- RGA와 RGASplit 성능이 비슷, RGATreeList와 RGATreeSplit도 성능이 비슷
- 예상한 대로 identifier 자료구조를 사용한 경우 upstream에서 매우 성능이 빨라짐
- downstream에서 identifier 자료구조 + RGA는 성능이 소폭 하락(identifier 자료구조 업데이트 해야 하므로)
5.4 블록 시리즈 수정
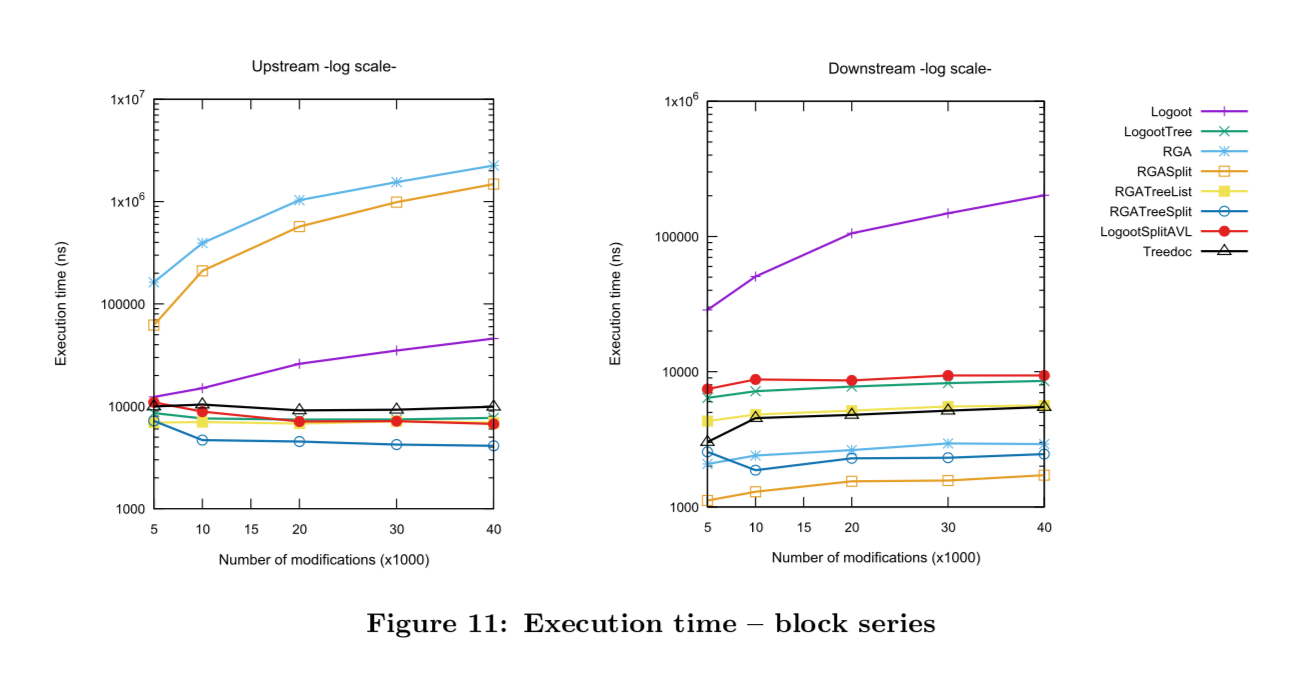
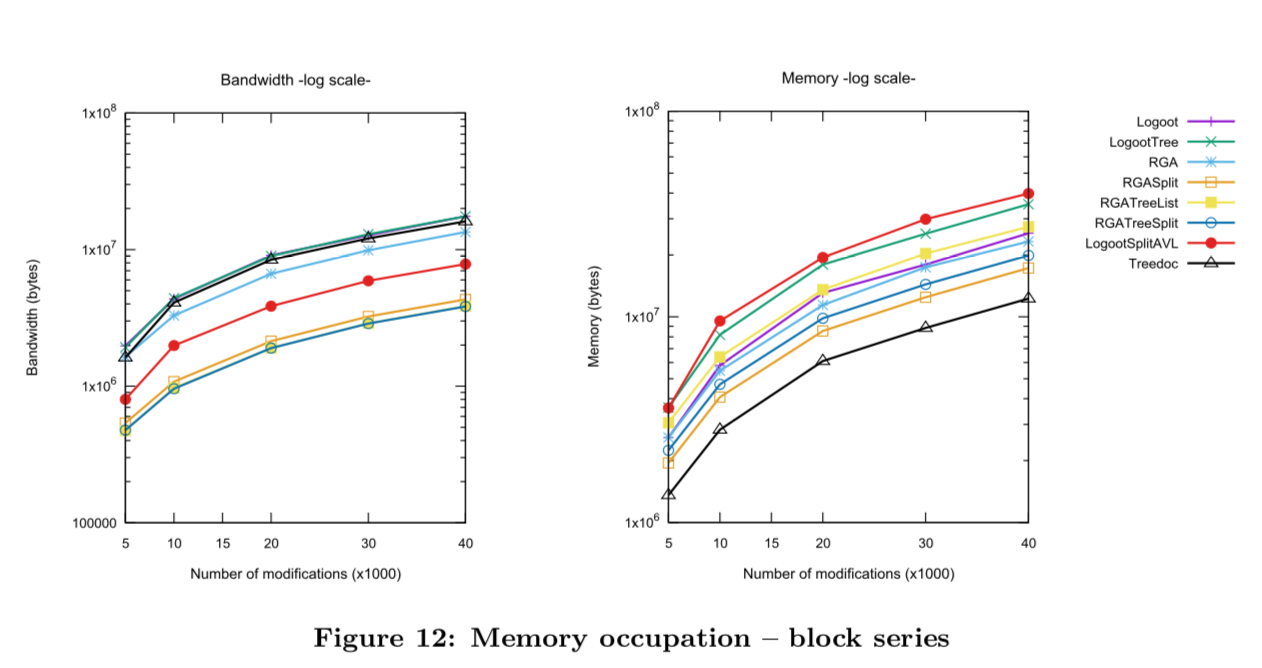
- 입력 오퍼레이션 특징: 80% 한 요소 수정과 20% 블록 수정, 블록의 평균 길이 20개
- 블록 기반 알고리즘이 기본 알고리즘보다 upstream과 downstream 모두에서 성능이 향상되었지만 빠른 응답을 위해 충분하지 않음
- RGASplit은 시간이 지남에 따라 성능이 저하 됨.
- LogootSplitAVL, TreeDoc은 원래의 RGA 알고리즘보다 다운 스트림 성능이 떨어짐
- RGATreeSplit은 전반적인 성능이 가장 좋음
- LogootTree는 RGATreeSplit보다 성능이 떨어지지만 블록 관리가 없어도 LogootSplitAVL과 유사한 성능 보임
6. 결론
이 논문에서는 CRDT 알고리즘의 응답성을 향상 시키기 위해서 블록 단위 알고리즘과 log 시간 복잡도를 위한 추가 identifier 자료구조를 제안한다. 특히, 사용자의 수정 사항을 반영하는 upstream 을 크게 개선되므로 체감 속도를 크게 향상된다.