A Conflict-Free Replicated JSON Datatype 요약
“A Conflict-Free Replicated JSON Datatype” 읽으면서 정리한 내용
요약
일반적으로 다양한 애플리케이션은 자신의 모델을 범용적인(general-purpose) 형식으로 모델링한다. 이 모델의 단일 복제본을 순차적으로 수정할 때에는 문제없지만, 여러 디바이스 로컬 저장소에서 각각 동시에 수정한다면, 어떤 값이 남아있어야 하는지 알기 어렵다. 이 논문은 CRDT를 이용해서 동시 수정으로 발생하는 충돌(conflict)를 자동으로 해결하는 JSON 자료구조를 제안한다. 이 자료구조에 적용된 알고리즘은 클라이언트에서 병합을 처리하고 모바일이나 열악한 네트워크 환경에도 적용 가능하다.
1. 도입
모바일 사용자는 오프라인시에도 계속해서 앱 사용이 가능하고 네트워크가 복구 될 때, 사용자의 다른 장비와 자동으로 동기화 되길 원한다. 이러한 종류의 앱은 캘린더, 주소록, 메모장, 할일 목록, 패스워드 등이있다. 또 협업 도구들은 여러 사용자가 문서 수정의 지연(delay)이 작은 환경에서 동시에 동일한 문서를 수정하는 기능을 필요로 한다.
이러한 애플리케이션은 보통 로컬에서 직접 수정가능 하도록 각각의 디바이스에 애플리케이션의 상태를 저장한다(optimistic replication). 종래의 접근 방식은 네트워크 환경이 열악한 경우 사용 불가능했다. 네트워크의 상태에 무관하게 애플리케이션이 항상 동작해야하는 경우, 서로 다른 장치에서 임의의 수정을 실행할 수 있어야 하며, 수정 결과로 발생하는 충돌을 해결할 수 있어야 한다.
가장 간단한 방법은 “last writer wins” 정책과 같이 충돌 발생시 특정 수정을 버려서 해결하는 것이지만 데이터 손실이 발생하므로 이러한 접근 방식이 적절하지 못할 때가 있다. 다른 대안으로 사용자가 수동으로 충돌을 해결하게 하는 방법이 있지만, 귀찮고 에러가 발생하기 쉬운 문제가 있다.
최근 애플리케이션들은 이 문제를 임기응변(ad-hoc)적이거나 애플리케이션 마다 자신들의 상황에 맞게 해결한다. 이 논문은 범용적인 JSON 데이터 모델로 표현 가능하고 정보 유실없이 동시 수정이 가능한 데이터타입을 제안한다. 이 접근 방식은 JSON 데이터타입에 대한 동시 수정을 자동으로 병합한다. 충돌 업데이트를 기록하기 위한 일반 메커니즘(multi-value register)를 제안한다. 이 메커니즘은 프로그램적으로 남아있는 충돌을 해결하는 일관된 기반을 제공한다.
1.1 JSON Data Model
JSON은 인기있는 범용 데이터 인코딩 포맷으로 다양한 데이터베이스나 웹서비스에서 사용한다. JSON에 추가로 스키마를 지정해서 제약할 수 있지만, 이 논문에서는 스키마가 없는 경우만 고려했다.
JSON 문서는 다음과 같이 두 형식의 브랜치(branch) 노드를 포함한 트리다. Map: 순서가 지정되지 않고 문자열 키로 찾을 수 있는 자식을 갖고 있는 노드. 논문에서는 키를 불변형, 값을 가변형으로 취급한다. List: 애플리케이션에서 지정한 순서의 자식을 갖고 있는 노드. 가변적이다.
브랜치 노드의 자식은 브랜치 노드 혹은 말단 노드(leaf)이다. 트리의 말단에는 기본 타입의 값(primitive value, [string, number, boolean, null])이 위치한다. 이 논문에서는 말단 노드의 값을 불변형으로 취급하고 해당 말단 노드를 수정시에 새로운 값으로 등록한다.
이 모델은 애플리케이션의 다양한 상태를 표현하는데 충분하다. 예를들어 텍스트 문서는 단일 문자의 리스트로 표현할 수 있다. 3.1 절에서는 더 복잡한 JSON으로 애플리케이션의 data를 모델링하는 예제를 살펴본다.
1.2 복제(replication)와 충돌 해결(conflict resolution)
이 논문은 JSON 문서의 본제본(replica)을 여러 디바이스에 갖고 자신의 복제본을 먼저 수정하고 비동기적으로 원격 복제본에 반영하는 시스템을 대상으로 한다(optimistic replication).
이 논문에서 필요로 하는 네트워크 환경은 하나의 복제본의 수정사항을 다른 모든 원격 복제본에 전달하는 네트워크를 필요로 한다. 네트워크는 임의적으로 지연되거나 순서가 뒤집히거나 중복 메시지가 발생할 수 있음을 가정한다.
이 논문이 다루는 범위는 클라이언트 측에 있고 메시지를 처리하거나 변환하는 서버가 필요 없으므로 P2P 네트워크에서도 사용할 수 있다.
4절에서는 서로 다른 디바이스에서 동시에 JSON 문서를 편집할 때 발생하는 충돌을 어떻게 해결하는지 다룬다. 이 논문의 디자인은 3가지 원칙을 기반으로 한다.
- 자료구조의 모든 복제본은 자동으로 동일한 상태로 수렴한다.
- 사용자의 입력은 동시 수정으로 인해 유실되지 않는다.
- 업데이트의 모든 조합의 순열들은 동일한 상태로 수렴한다.
1.3 이 논문의 공헌 내용
이 논문이 공헌한 점은 JSON 자료구조의 동시 수정 발생시 자동으로 충돌을 해결하는 알고리즘을 정의한 것이다. 이전에도 리스트, 맵, 레지스터와 같은 자료형이 개별적으로 제안되었으나 이 논문은 각각의 자료구조를 통합하고 어떤 네트워크 토폴로지에 사용할 수 있도록 했다.
맵과 리스트의 중첩 자료구조를 구성하면 트리의 서로 다른 레벨을 동시에 수정하는 것이 가능하기 때문에 단일 자료구조에서 발생하지 않는 문제가 발생한다. 이 문제들은 3.1 절에서 다룬다. 중첩 데이터 구조는 많은 애플리케이션의 중요한 요구사항이다.
2. 관련 작업
2.1 Operation Transformation
OT 기반 알고리즘은 동시편집 애플리케이션에서 오랫동안 사용되었다. 이 애플리케이션들은 대부분 문자열을 원소로하는 단일 리스트를 문서로 다루며 충첩 트리 자료구조를 지원하지 않는다. XML 문서를 편집하기 위해서 OT를 일반화한 일부 알고리즘은 충첩 리스트를 다뤘으나 이 논문이 다루는 충첩 맵을 다루지는 않았다. 또 OT 알고리즘은 동시에 발생하는 오퍼레이션의 수가 증가하면 급격히 성능이 저하된다.
대다수의 OT 기반의 협업 시스템(Google Docs, Etherpad, Novell Vibe, Apache Wave)은 오퍼레이션의 순서를 결정하기 위한 단일 서버를 필요로 하는데, 이 디자인 개념은 Jupiter 시스템에서 왔다. 이 접근 방식은 변환 함수를 단순화하고 오류 발생을 줄이지만 P2P에서 사용할 수 없었다.
협업 작업에 사용할 많은 보안 메시징 프로토콜은 각각의 수신자가 메시지를 동일한 순서로 볼 수 없을지도 모른다. Atomic broadcast 프로토콜을 사용하면 서버 없이도 오퍼레이션의 전체 순서를 보장할 수 있지만, 합의(consensus) 프로토콜과 마찬가지로 쿼럼에 각 노드들이 접근가능할 때에만 안전하게 처리한다. 이 P2P 시스템에서의 모바일 디바이스는 자주 오프라인이 되고 atomic broadcast는 쿼럼에 접근하기 위해서 문제가 발생해서 사용하기 어려울 것이다. 쿼럼 없이 이를 처리할 수 있는 방식은 causal ordering 이다.
Google Realtime API는 임의의 중첩 리스트와 맵을 OT로 구현했고 Google Docs처럼 서버를 필요로 한다. 자세한 알고리즘은 아직 발표되지 않았다.
2.2 CRDT
CRDT는 동시 편집을 지원하는 자료구조로 동시 수정의 수렴을 보장하며 데이터타입에 메타데이타를 추가해서 생성시 오퍼레이션이 교환법칙(commutative)이 가능하도록 한다. 이 논문은 CRDT JSON 데이터타입을 다룬다.
CRDT를 기반으로한 레지스터(register), 카운터(counter), 맵, 셋(sets)은 Riak과 같이 다양한 출시된 시스템에서 사용된다. 순서 리스트의 알고리즘은 WOOT, RGA, Treedoc, Logoot, LSEQ등 여러가지가 제안되었지만 모두 기본형 값을 사용하고 값으로 다른 CRDT를 갖는 충첩을 지원하지는 않았다.
충첩 CRDT에 대한 연구는 최근에 진행되었다. Riak은 맵안에 카운터와 레지스터, 맵의 중첩이 가능했다. (생략…) 이 연구들 모두 리스트를 중첩하지는 않았지만, 이 논문에서 사용하는 의미체계의 기초가 된다. (생략…) 레지스터, 맵, 리스트들이 수년간 개별적으로 연구되었고 이 논문은 JSON 유사한 구조의 임의의 중첩 CRDT를 제안한다.
2.3 다른 접근 방법
복제된 데이터 시스템은 동시 수정과 충돌을 해결해야 하지만, 기존에는 이 문제를 각 애플리케이션 마다 임기응변으로 해결했다. 예를 들어, Dynamo와 CouchDB는 여러 값이 같은 키에 동시에 쓰여지면 데이터베이스는 이러한 모든 값을 보존하고 충돌 해결을 애플리케이션에서 처리하도록 한다.(생략…)
충돌 해결에 자주 사용하는 또 다른 접근법은 LWW(last writer wins)로, 여러 동시 수정 중 하나를 “승자”로 선택하고 다른 기록을 삭제한다. LWW는 Apache Cassandra에서 사용된다. 동시 수정으로 인해 사용자 입력이 손실되는 단점이 있다.
트리 구조에 대한 동시 편집을 해결하는 것은 파일 동기화 분야에서 연구되었다. 마지막으로 Bayou에서는 오프라인 노드가 일시적으로 트랜잭션을 실행하고 다음 온라인 상태 일 때 이를 확인하는데 동일한 일련 순서로 트랜잭션을 실행하는 모든 서버에 의존이 있고 트랜잭션이 전제 조건에 따라 성공했는지 여부를 결정한다. Bayou는 직렬화가 필요하고 CRDT를 사용하여 표현할 수 없는 유일성 제약 조건과 같은 전역 불변량을 표현할 수 있다는 장점이 있다. Bayou의 단점은 애플리케이션이 명시적으로 처리해야하는 임시 트랜잭션이 롤백 될 수 있다는 점이고 CRDT는 하나의 복제본에서 수행 된 작업이 실패하지 않는다.
3. 자료구조 구성
3.1 동시 편집 예
JSON 자료구조를 순차적으로 편집하는 의미론은 잘 알려져 있으며, 플랫한 맵 또는 리스트의 동시 편집은 기존 논문에서 철저히 조사되었다. 그러나 JSON CRDT에서 동시성과 중첩 된 데이터 구조 간의 상호 작용으로 인해 문제가 발생한다.
다음 예제는 JSON 문서가 동시에 수정 될 때 발생할 수있는 몇 가지 상황을 보여 주며, 이 논문에서 제시한 알고리즘에 의해 처리되는 방법에 대해 알아본다. 예제에서는 p와 q라는 두 개의 복제본을 가정한다.복제본의 로컬 상태는 박스에 그렸고 로컬 상태의 수정 내용은 레이블이 있는 실선 화살표로 표시한다. 시간은 아래로 흐른다. 복제본은 로컬 상태만 변경하기 때문에 복제본 간에 변경에 대해서만 통신한다. 네트워크 통신은 점선 화살표로 표현했다.
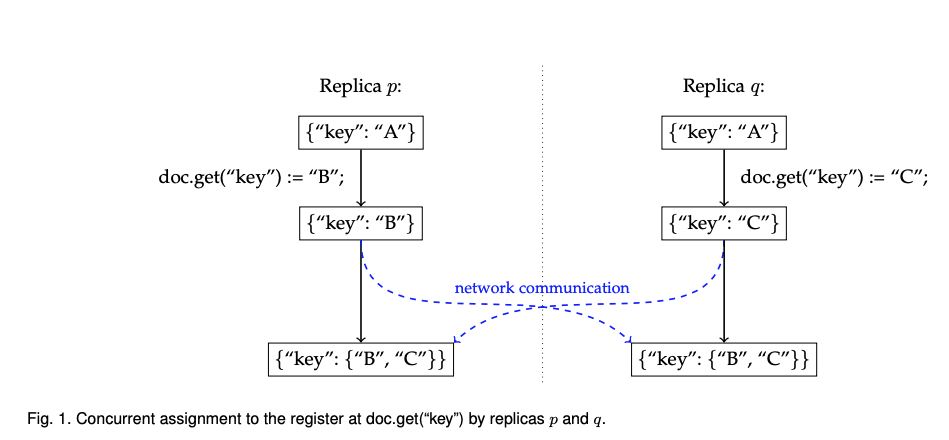
그림 1에서는 키가 “key”이고 값이 “A”을 갖은 문서에서 리플리카 p는 값을 “B”로 설정하고 리플리카 q는 동시에 “C”로 설정한다. 이후 네트워크 통신을 통해 편집 내용을 받으면 충돌을 감지한다. 문자열 “B”와 “C”를 의미있게 병합 할 수 없기 때문에 시스템은 동시에 발생한 두 업데이트를 보존해야 한다. 이 데이터 유형은 다중 값 레지스터(multi-value register)로 불린다. 복제본은 레지스터에 단일 값만 할당 할 수 있지만 읽기시에 동시에 쓰인 값의 집합이 반환된다.
다중 값 레지스터는 충돌 해결을 실제로 수행하지 않으므로 인상적인 CRDT는 아니다. 이 논문에서는 자동 병합 함수가 정의되지 않은 기본형에만 이 방식을 취한다. 하지만 다른 CRDT는 이를 처리한다(예 : 카운터 CRDT 또는 공동 편집에 사용하는 정렬된 리스트 CRDT).
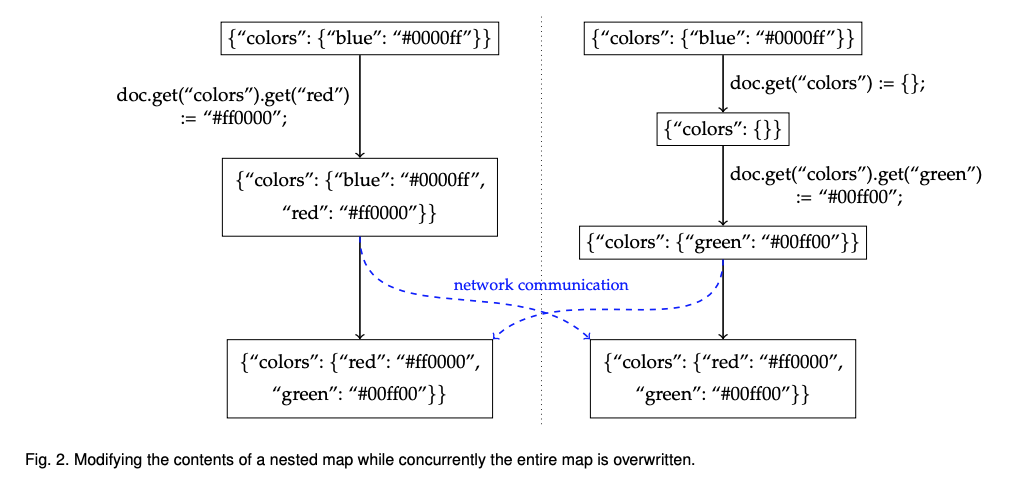
그림 2에서는 JSON 트리에서 다양한 레벨에서의 동시 편집의 예를 표현했다. 여기서 리플리카 p는 colors 맵에 “red”를 추가하고 동시에 리플리카 q는 colors 맵을 지운 다음 “green”을 추가한다. 빈 맵을 할당하는 대신, q는 colors 맵의 키를 제거한 다음 해당 키에 새 값을 할당한다. 이 예제의 어려움은 트리의 하위 레벨에서 “red”를 추가하는 것과 동시에 트리의 상위 레벨에서 colors 맵이 제거된다는 점이다.
레벨간 충돌을 처리하는 방법중 하나는 트리의 상위에서 발생한 편집이 항상 해당 하위 트리에서 발생한 동시 편집을 무시하는 것이다. 이 경우, “red”의 추가는 상위 삭제(blanking-out)에 의해 무시되기 때문에 버린다. 그러나 이러한 동작은 동시 수정으로 인해 사용자 입력을 잃지 않아야 한다는 초기 요구 사항을 위반한다. 따라서 논문에서는 그림 2와 같이 모든 변경 사항을 보존하는 병합 의미론을 정의했다. “blue”는 최종 맵에서 제거되어야 하며 “빨간색”과 “녹색”은 명시 적으로 추가 되었기 때문에 맵에 추가되어야 한다. 이 동작은 Riak 의 CRDT 맵의 동작과 일치한다.
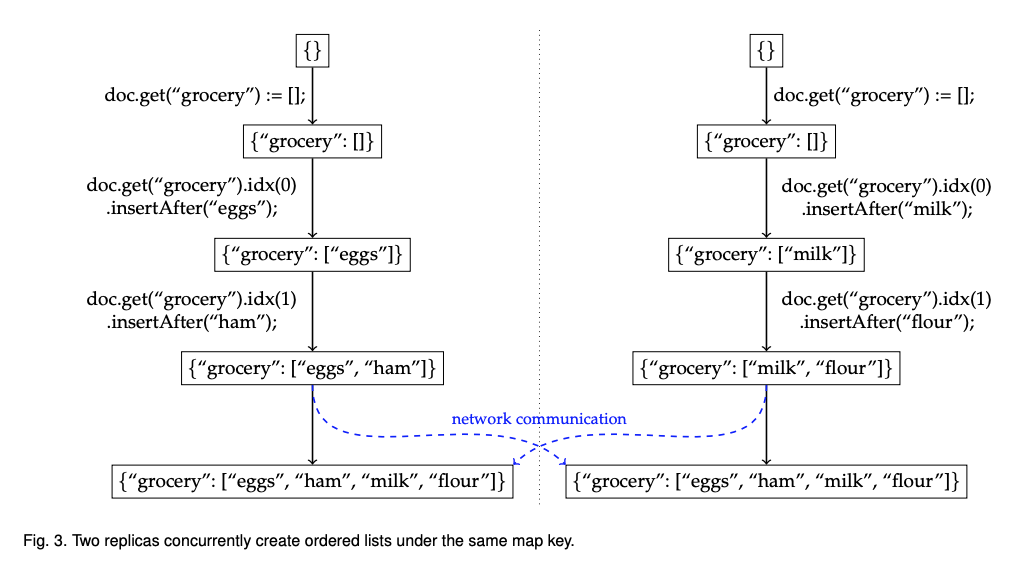
그림 3은 동일한 키의 리스트에서 발생하는 문제점을 표현했다. 두 개의 복제본이 동시에 동일한 키에 값을 삽입했을 때, p와 q는 각각 독립적으로 동일한 맵에 “grocery”키로 리스트를 만들고 리스트에 항목을 추가한다. 그림 1의 경우, 동일한 맵 키에 대한 동시 할당은 애플리케이션에 의해 해결했지만, 그림 3에서 두 값은 리스트에서 자동으로 병합한다. 각 복제본에 삽입 된 항목의 순서와 인접성을 보존하므로 병합 결과에서 “eggs”뒤에 “ham”이 있고 “milk”뒤에 “flour”가 추가된다. 어떤 복제본의 항목이 병합 된 결과에서 처음으로 나타 나야하는지에 대한 정보는 없으므로 “eggs, ham, milk, flour”와 “milk, flour, eggs, ham”중 하나가 선택된다. 단, 모든 복제본은 동일한 순서로 병합된다.
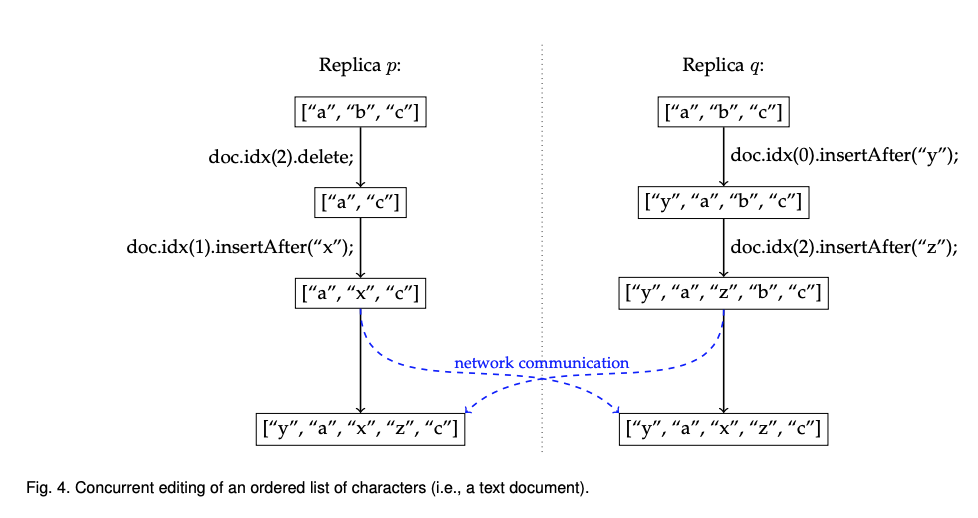
그림 4는 문서를 문자 리스트로 처리해서 협업 텍스트 편집기를 구현하는 방법을 표현했다. 병합 된 결과에 모든 변경 사항이 보존된다. “a”앞에 “y”가 삽입, “x”와 “z”는 “a”와 “c”사이에 삽입 “b”는 삭제됨.
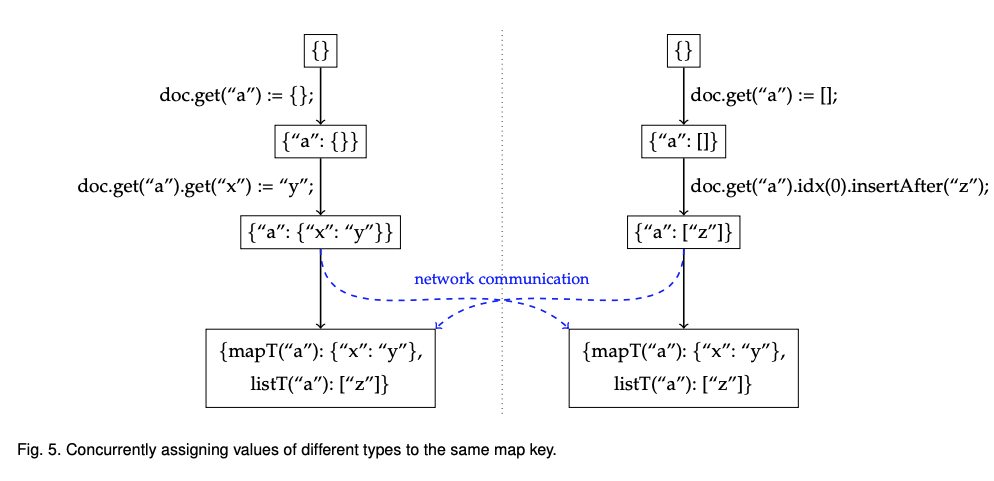
그림 5는 그림 3처럼 두 개의 복제본이 동시에 동일한 맵 키를 삽입 했지만 다른 타입을 값으로 할당하는 문제를 표현했다. p는 중첩 맵을 삽입했고 q는 리스트를 삽입했다. 이러한 데이터 유형은 의미있게 병합할 수 없으므로 두 값을 별도로 보존한다. 이 논문은 맵의 각 키에 map, list, register 값에 대한 타입 주석(mapT, listT, regT)을 태깅해서 각 유형이 별도의 네임 스페이스를 유지하도록 했다.
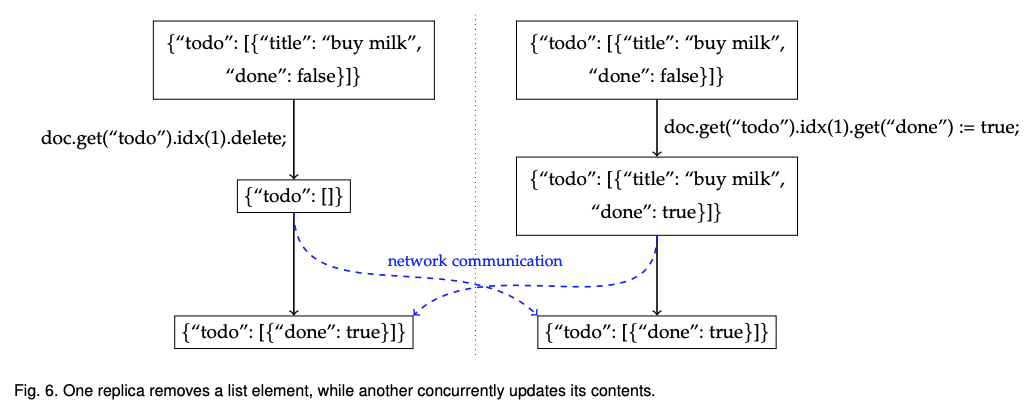
마지막으로, 그림 6은 모든 사용자 입력을 보존하는 원칙의 한계를 표현했다. p가 항목을 리스트에서 제거하는 동시에 q는 항목을 완료로 표시한다. 변경 사항이 병합되면 맵 키 “done”이 참인 제목이 없는 값이 남는다. 이 동작은 그림 2에서는 정상 동작하지만 여기에서는 오류를 범한다. 이 경우, 동시 갱신 중 하나를 버리고 작업 항목에 “제목”및 “완료” 필드가 있는 내재적 스키마를 보존하는 것이 더 바람직하다.
3.2 JSON vs XML
JSON의 일반적인 대안은 XML로 협업 편집은 이전에 연구되었다. XML과 JSON의 트리 구조는 매우 유사하지만 중요한 차이가 있다.
JSON에는 임의의 맵과 리스트를 중첩 할 수 있는 구조를 갖고 있다. 반면 XML은 자식으로는 리스트를 갖고 attribute는 맵을 갖지만 중첩 구조를 허용하지 않는다. 따라서 XML은 리스트는 값으로 맵을 지원하지만 맵은 값으로 리스트를 지원하지 않는다. 따라서 XML은 JSON보다 표현력이 부족하다. 그림 3과 5의 시나리오는 XML에서 구현할 수 없다. 일부 애플리케이션은 XML 문서의 하위 attribute에 맵과 유사한 의미를 첨부하지만 이 구조는 XML 자체의 특성은 아다. 동일한 키를 가진 자식이 여러 개 동시에 생성되는 경우 기존 알고리즘은 그림 3과 같이 병합하지 않고 동일한 키를 가진 중복 자식을 만들어야한다.
3.3 문서 편집 API
협업 가능한 데이터 구조에 대한 의미(semantics)를 정의하기 위해 먼저 모든 복제본에서 로컬에 실행하며 해당 복제본을 쿼리하고 수정할 수 있는 간단한 명령 언어(command language)를 그림 7처럼 정의한다. 읽기 쿼리를 수행하면 부작용(side effect)이 없지만 문서를 수정하면 부작용이 발생하는 작업이 생성된다. 이러한 작업은 문서의 로컬 복사본에 즉시 적용되며 다른 복제본에 비동기(asynchronous)로 브로드 캐스팅 큐에 추가된다.
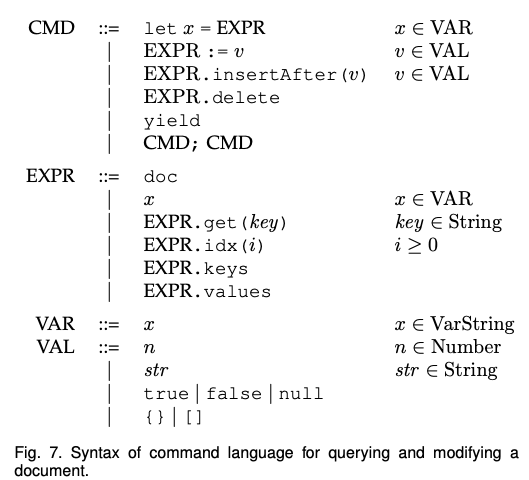
명령 언어의 구문(syntax)은 그림 7에 있다. 완전한 프로그래밍 언어가 아니라 문서 상태를 쿼리하고 수정하는 API이다. 애플리케이션은 사용자 입력을 받아 API에 일련의 명령(무한한)을 발행한다. API는 일관된 병합 의미를 정의 할 수 있도록 많은 프로그래밍 언어에서 발견되는 JSON 라이브러리와 약간 다르다.
먼저 공식적인 의미를 부여하기 전에 언어를 비공식적으로 설명한다. 표현식 구조 EXPR은 문서의 위치를 식별하는 커서를 구성하는 데 사용된다. 표현식(expression)은 JSON 문서 트리의 루트를 식별하는 특수 토큰 doc 또는 let 명령에서 이전에 정의 된 변수 x로 시작한다. 이 표현식은 왼쪽에서 오른쪽으로 트리가 잎을 향해 잎을 향해 이동할 때 커서가 취하는 경로를 정의한다. 연산자 .get (key)는 맵에서 키를 선택하고 .idx (n)은 정렬 된 순서의 n 번째 요소를 선택한다.
또한 EXPR은 문서의 상태 질의가 가능하다. keys는 현재 커서에서 맵의 키들을 반환하고, values는 현재 커서의 다중 값 레지스터의 내용을 반환한다. 명령 CMD는 로컬 변수(let)의 값을 설정하거나 네트워크 통신 (yield)을 수행해서 문서를 수정한다. 문서는 리스트에 요소를 삽입하여 레지스터(연산자 : =는 레지스터 값을 할당)에 쓰거나 (insertAfter는 커서로 식별 된 기존 요소 다음에 새 요소를 배치) 또는 리스트 또는 맵에서 요소를 삭제할 수 있다(delete는 커서로 식별 된 요소를 삭제).

그림 8은 쇼핑리스트를 표현하는 새로운 문서를 구성하는 명령들의 예다. 먼저 문서는 빈 맵 리터럴 인 {}로 설정되고 그 맵 내의 키 “shopping”은 빈 리스트 []로 설정한다. 세 번째 행은 “shopping”키로 이동하여 리스트의 헤드(head)를 선택하여 커서를 head라는 변수에 할당한다. 리스트 요소 “eggs”가 리스트의 헤드에 삽입된다. 5 행에서 변수 egg는 리스트 요소 “eggs”를 가리키는 커서로 할당된다. 그런 다음 헤드에 “cheese”, “eggs”뒤에 “milk”라는 두 가지 요소가 삽입된다. 커서 eggs는 색인에 의해서가 아니라 ID에 의해 리스트 요소를 식별한다. “cheese” 삽입 후 요소 “eggs”은 index 1에서 2로 변경되지만 “milk”는 “eggs” 다음에 삽입된다. 나중에 보게 되겠지만, 이 기능은 동시 수정이있을 때 바람직한 의미를 얻기 위해 유용하다(Cursor).
4. 형식 의미론(Formal Semantics)
이어서 3절에서 알아본 동시 의미론을 성취하는 방법을 형식적으로 설명한다. 리플리카 p의 상태는 유한 부분 함수(finite partial function) 인 Ap에 의해 설명된다. 명령 언어의 평가 규칙은 로컬 상태 Ap를 검사하고 수정하며 Aq(다른 리플리카 q는 p와 다름)와 의존성이 없다. 복제본 간의 유일한 통신은 yield 명령을 평가할 때 발생하는데, 이는 나중에 알아본다. 지금은 단일 복제본 p의 명령 실행에 대해 집중적으로 알아본다.
4.1 표현식 평가(Expression Evaluation)

그림 9는 명령 언어에서 EXPR 표현식을 평가하는 규칙이며 로컬 복제본 상태 Ap의 컨텍스트에서 평가된다. EXEC 규칙은 명령이 순차적으로 실행된다는 가정을 공식화했다. LET 규칙은 프로그램이 로컬 상태에 추가한 로컬 변수를 정의하도록 한다(표기법 Ap [x → cur]은 Ap와 동일하지만 Ap(x) = cur을 제외한 부분 함수를 나타냄). VAR 규칙은 애플리케이션이 이전에 정의한 변수의 값을 검색 할 수 있게한다.
이어지는 규칙은 표현식이 커서로 평가되는 방법을 표현했다. 이는 문서 트리의 루트에서 일부 브랜치 또는 리프 노드까지의 경로를 나타내며 JSON 문서의 특정 위치를 모호하지 않게 식별한다. 커서는 변경 불가능한 키와 식별자로만 구성되므로 네트워크를 통해 다른 복제본으로 보낼 수 있다.

예를 들어, id (1)이 이 리스트를 삽입 한 작업의 고유 식별자라고 가정 할 때, cursor(mapT(doc), listT( “shopping”), id1)는 그림 8의 리스트 요소 “eggs”를 나타내는 커서이다. 요소 (4.2.1절에서 이 식별자들에 대해 알아본다). 커서는 로컬 복제본 상태 구조 Ap를 통해 경로로 해석되며 왼쪽에서 오른쪽으로 순서로 루트의 doc 맵에서 시작해서 listT 타입의 “shopping” 항목을 탐색하고 ID가 1인 식별자인 리스트 요소로 끝난다. 일반적으로, 커서(<k1, …, kn-1>, kn)는 키 k1,. . . , kn-1과 항상 존재하는 최종키(kn)으로 구성된다. kn은 벡터의 마지막 요소인데, 벡터의 다른 요소에는 traversal 되는 분기 노드의 데이터 유형으로 mapT 또는 listT 태그가 지정되는 반면 데이터 유형이 태깅되지 않는다는 점이 다르다.
그림 9의 DOC 규칙은 특수 원자 doc를 사용하여 문서의 루트를 참조하는 가장 간단한 커서(hi, doc)를 정의한다. GET 규칙은 커서로 맵의 특정 키로 이동한다. 예를 들어, doc.get( “shopping”) 표현식은 DOC 및 GET 규칙을 적용하여 cursor(<mapT(doc)>, “shopping”)로 평가된다. doc.get(…) 표현식은 doc가 mapT 유형임을 암시적으로 나타낸다.
규칙 IDX1…5는 .idx(n)표현식을 평가하여 커서를 리스트의 특정 요소로 이동시키는 방법을 정의한다. IDX1은 리스트의 헤드를 나타내는 커서를 구성하고 이어지는 규칙에 위임해서 리스트를 검사한다. IDX2는 커서의 키 벡터에 따라 로컬 상태를 재귀적으로 찾아낸다. 키 벡터가 비어있을 때 컨텍스트 ctx는 문제의 리스트를 저장하는 Ap의 하위 트리이며 규칙 IDX3, 4, 5는 원하는 요소가 발견 될 때까지 해당 리스트에 반복 수행한다. IDX5는 인덱스가 0에 도달하면 반복문을 종료하고 IDX3은 다음 요소로 이동하여 인덱스를 감소 시키며 IDX4는 삭제 됨으로 표시된 리스트 요소를 건너뛴다. 이 구조는 링크드리스트과 유사하다(각 리스트 요소는 고유 한 식별자 k와 k 다음에 오는 요소의 ID를 구하는 next(k) 부분 함수를 갖음).
삭제된 요소는 링크드 리스트 구조에서 제거되지 않지만 삭제 된 것으로 표시하는데(tombstone) 이를 위해 요소에 대한 존재 여부를 알 수 있는 pres(k)를 유지한다. 리스트 요소가 삭제되면 pres 집합에서 제거해서 삭제로 표시한다. 그러나 리스트 요소를 참조하는 일은 동시 작업으로 인해 pres 세트가 다시 비어 있지 않게 될 수 있다(그림 2 및 6의 상황을 초래). 규칙 IDX4는 색인을 감소시키지 않고(즉, 리스트 요소로 계산하지 않음) 다음 요소로 이동한다.
KEYS1, 2, 3 규칙은 애플리케이션이 맵에서 키 집합을 검사 할 수있게 한다. 이 집합은 로컬 상태를 검사하고 현재 상태 집합이 비어있는 키를 제외하여 결정된다(키가 삭제되었음을 나타냄). 마지막으로, VAL1,2,3 규칙은 IDX 규칙과 유사한 재귀적 규칙 구조를 사용하여 애플리케이션이 특정 커서 위치에서 레지스터의 내용을 읽을 수 있게한다. 레지스터는 로컬 상태의 regT 유형 주석을 사용하여 표현된다. 복제본은 레지스터에 단일 값만 할당 할 수 있지만 여러 개의 복제본이 동시에 값을 할당하면 레지스터에 여러 값이 포함될 수 있다.
4.2 오퍼레이션 생성하기
오퍼레이션(Operation)은 문서의 상태를 명령(command)으로 변경하면 발생하는 변환(mutation)을 표현한다. 이 논문의 의미론에서, 명령은 로컬 복제 상태 Ap를 직접 수정하지 않고 오퍼레이션만 생성 한 뒤 즉시 Ap에 적용되고 동일한 오퍼레이션이 다른 복제본에도 비동기적으로 브로드캐스팅된다.
4.2.1 램포트 시계(Lamport timestamp)
모든 오퍼레이션에는 로컬 상태와 커서에서 사용되는 고유 한 식별자(unique identifier)가 제공된다. 요소가 리스트에 삽입되거나 값이 레지스터에 할당 될 때마다 새 리스트 요소 또는 레지스터 값은 이를 생성한 작업의 식별자로 구분된다. 복제본 간의 동기 조정을 필요로하지 않고 전역적으로 고유한 작업 식별자를 생성하기 위해 램포트 시계를 사용한다. 램포트 시계는 Pair(c, p)이며, 여기서 p ∈ ReplicaID는 편집이 이루어진 복제본의 유일한 식별자 (예 : 공개 키의 해시)이고 c ∈ N은 저장된 카운터로 각 복제본에서 모든 작업에 대해 증가한다. 각 복제본은 엄격하게 단조(monotonically) 증가하는 카운터 값 c의 시퀀스를 생성하므로 Pair (c, p)는 고유하다. 복제본이 로컬에 저장된 카운터 값보다 큰 카운터 값 c를 갖는 연산을 수신하면 로컬 카운터는 수신 받은 카운터의 값으로 증가한다. 이렇게하면 o1가 o2보다 먼저 발생하는 경우(즉, o2를 생성 한 복제본이 o2가 생성되기 전에 o1을 받고 처리 한 경우) o2가 o1보다 큰 카운터 값을 가져야한다. 동시 작업만 동일한 카운터 값을 가질 수 있다. 램포트 시계로 오퍼레이션에 대해 전체 정렬을 할 수 있다.
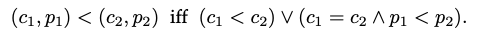
한 작업이 다른 작업보다 먼저 발생하면 이 순서는 인과 관계와 일치한다(이전 작업의 timestamp가 더 낮음). 두 작업이 동시에 수행되는 경우 < 에 따른 순서는 임의적(arbitrary)이지만 결정적(deterministic)이다. 이 정렬 속성은 정렬 된 리스트의 의미론 정의에 중요하다.
4.2.2 오퍼레이션 구조
오퍼레이션은 튜플로 id는 오퍼레이션을 식별하는 램포트 시계, cur는 변경의 문서 내의 위치를 나타내는 커서, mut는 지정된 위치의 변환, deps는 인과 관계가 의존된 오퍼레이션의 집합이다.

o2가 replica p에 의해 생성 된 경우, o2의 인과 관계는 o2가 생성 된 시점에 이미 p에 적용된 모든 연산이다. 이 논문에서, 모든 인과 관계의 램포트 시계 집합으로 deps를 정의한다. 실제 구현에서는 이 집합이 비실용적으로 커지므로 인과 관계의 간략한 표현이 대신 사용된다(예 : 버전 벡터, 상태 벡터 또는 점선 버전 벡터). 그러나 의미론에서 모호성을 피하기 위해 의존성을 간단한 오퍼레이션 ID 세트로 설명한다. 인과 관계 종속성의 목적은 오퍼레이션에 부분적 순서를 부여하는 것이다. 오퍼레이션은 “이전에 발생한 모든 작업”이 적용된 후에 만 적용될 수 있다. 특히 특정 복제본에서 생성된 작업 시퀀스가 다른 모든 복제본에서 동일한 순서로 적용된다는 의미이다. 동시 작업(즉, 어느 방향으로도 인과 관계가없는 경우)은 임의의 순서로 적용 할 수 있다.
4.2.3 오퍼레이션 의미론(Semantics of Generating Operations)

MAKE-ASSIGN, MAKE-INSERT 및 MAKE-DELETE 규칙은 명령이 문서를 어떻게 변경시키는 지 정의한다. 셋 모두 MAKE-OP 규칙에 위임하여 작업을 생성하고 문서에 반영한다. MAKE-OP는 복제본 p에 적용된 모든 작업 ID 집합인 Ap(ops)의 기존 카운터보다 1만큼 큰 카운터 값을 선택하여 새로운 램포트 시계를 생성한다. MAKE-OP는 위에 설명 된 양식의 op() 튜플을 구성하고 APPLY-LOCAL 규칙에 위임하여 작업을 처리한다. APPLY-LOCAL은 다음 세 가지 작업을 수행한다.
- 오퍼레이션을 평가하고 수정된 로컬 상태 Ap’를 생성
- 생성된 오퍼레이션 대기열 Ap(queue)에 오퍼레이션을 추가
- 해당 ID를 처리 된 연산 집합 Ap(ops)에 추가.
(Burckhardt et al.에서 영감을 받은) yield 명령은 다른 복제본과의 작업 송수신 및 원격 복제본의 작업 적용하는 네트워크 통신을 수행한다. APPLY-REMOTE, SEND, RECV 및 YIELD 규칙은 yield의 의미를 정의한다.
이러한 규칙 모두 네트워크의 비동기성을 모델링인 yield를 평가하는데 사용하기 때문에 비결정적(nondeterministic)이다. 하나의 복제본에서 보내는 메시지는 임의의 차후 시점에 다른 복제본에 도착하며, 메시지 순서의 보장은 없다. 네트워크에서 SEND 규칙은 APPLY-LOCAL에의해 Ap(queue)에 배치된 모든 작업을 가져 와서 송신 버퍼 Ap(send)에 추가한다. 따라서 RECV 규칙은 복제본 q의 전송 버퍼에서 작업을 수행하여 복제본 p의 수신 버퍼 Ap(recv)에 추가한다. 이것은 하나 이상의 복제본을 포함하는 유일한 규칙이며 모든 네트워크 통신에 적용 가능하다.
수신 버퍼 Ap(recv)에 오퍼레이션이 추가되면 APPLY-REMOTE 규칙을 적용할 수 있다. 작업이 아직 처리되지 않았고 해당 인과 관계가 충족된다는 전제하에 APPLY-REMOTE는 APPLY-LOCAL과 같은 방식으로 오퍼레이션을 적용하고 ID를 처리 된 작업 집합 Ap(ops)에 추가한다. 실제 문서 수정은 다음 절에서 알아본다.
4.3 오퍼레이션 적용하기

그림 11은 오퍼레이션 op를 컨텍스트 ctx에 적용하여 업데이트 된 컨텍스트 ctx0을 생성하는 규칙을 나타낸다. 컨텍스트는 초기에 복제 상태 Ap이지만, 규칙들이 재귀적으로 반영될 때 상태의 서브 트리를 참조하기도 한다. 이 규칙들은 APPLY-LOCAL 및 APPLY-REMOTE가 문서의 상태 업데이트를 수행하는 데 사용된다.
오퍼레이션 커서의 키 벡터가 비어 있지 않으면 먼저 DESCEND 규칙이 적용된다. 키에 설명한 경로를 따라 문서 트리를 재귀적으로 따라간다. 트리 노드가 로컬 복제본 상태에 이미 존재하면 CHILD-GET가 이를 찾는다. 그렇지 않으면 CHILD-MAP과 CHILD-LIST가 각각 빈 맵 또는 리스트를 생성한다.
또한 DESCEND 규칙은 커서에 의해 기술 된 경로를 따라 각 트리 노드에서 ADD-ID1, 2를 호출하고, pres(k)에 오퍼레이션 ID를 추가하여 서브 트리가 이 오퍼레이션에 의해 만들어진 변환을 포함함을 나타낸다.
그림 11의 나머지 규칙은 커서에 있는 키의 벡터가 비어있는 경우에 적용된다. 이는 변환이 적용되는 트리 노드의 컨텍스트로 내려갈 때 적용된다. ASSIGN 규칙은 레지스터에 기본형 값을 할당하는 것을 처리하고, EMPTY-MAP은 값이 빈 맵 리터럴 {}, EMPTY-LIST가 빈리스트 []의 할당을 처리한다. 이러한 세 가지 할당 규칙은 유사한 구조를 갖는다. 먼저 커서에서 이전 값을 지우고(다음 절에서 설명), 오퍼레이션 ID를 현재 pres 집합에 추가 한 다음 마지막으로 새 값을 로컬 상태 트리에 통합한다.
INSERT1,2 규칙은 순서가 지정된 리스트에 새 요소의 삽입을 처리한다. 이 경우 커서는 list 요소 prev를 참조하고 새 요소는 리스트의 해당 위치 다음에 삽입된다. INSERT1은 링크드 리스트 구조를 조작하여 삽입을 수행한다. INSERT2는 동일한 위치에 리스트 요소를 동시에 삽입하는 다중 복제본의 경우를 처리하고 램포트 시계의 순서 관계를 사용하여 일관되게 삽입 지점을 결정한다. 논문의 삽입 처리에 대한 접근법은 RGA 알고리즘에 기반을 두고있다. 이 규칙은 모든 복제본이 동일한 상태로 수렴된다는 것을 보여준다.
4.3.1 이전 상태 정리하기
할당 및 삭제 작업은 그림 2와 같이 동시에 이전 상태(덮어 쓰거나 삭제 된 값)가 지워지는 동시 수정이 손실되지 않도록 해야한다. 이 지우기 프로세스를 처리하는 규칙은 그림 12에 있다. 무언가를 지우는 효과는 동시 작업의 영향을 받지 않은 채로 현재 작업의 원인이되는 작업을 취소하여 빈 상태로 다시 설정하는 것이다.
삭제 연산은 커서가 가리키는 리스트의 요소나 맵의 키에서 삭제한다. DELETE 규칙은 CLEAR-ELEM에 위임하여 이 오퍼레이션을 평가한다. 차례대로 CLEAR-ELEM은 mapT, listT 또는 regT 유형인지 여부에 관계없이 CLEAR-ANY를 사용하여 지정된 키가 있는 데이터를 지우고 중첩된 작업 ID를 포함하도록 현재 상태를 업데이트하고 deps의 기존 오퍼레이션들을 제거한다.
CLEAR-ANY은 해당 키가 ctx에 나타나면 CLEAR-MAP1, CLEAR-LIST1 및 CLEAR-REG로 처리하고 키가 없는 경우 CLEAR-NONE(아무 것도 수행하지 않음)으로 처리한다.
ASSIGN 규칙에 정의한 것 처럼 레지스터는 오퍼레이션 ID에서 값의 맵핑을 관리한다. CLEAR-REG는 deps에 나타나는 모든 오퍼레이션 ID(즉, 삭제 작업보다 먼저 발생 함)를 삭제하지만 deps에 표시되지 않는 모든 오퍼레이션 ID(삭제 작업과 동시에 발생하는 할당 오퍼레이션)를 유지하여 레지스터를 업데이트한다. 맵과 리스트 지우기도 비슷한 접근 방식을 취한다. 각 요소는 clearElem을 사용하여 재귀적으로 지워지고 pres 집합은 deps를 제외하도록 업데이트된다. 따라서, 정리 오퍼레이션 이전에 변경이 발생하는 모든 리스트 요소 또는 맵 항목은 빈 존재 세트로 끝날 것이므로 삭제 된 것으로 간주된다. 지우기 오퍼레이션과 동시에 수행되는 오퍼레이션을 포함하는 맵 또는 리스트 요소는 보존된다.

4.4 수렴(Convergence)
1.2 절에서 설명한 핵심 요구 사항처럼 CRDT의 모든 복제본은 자동으로 동일한 상태로 수렴되어야한다. 이제 이 개념을 공식화하고 그림 9~12의 규칙이 이 요구 사항을 충족함에 대해 알아본다.

정의 1 (유효한 실행). 유효한 실행은 일련의 복제본 {p1,. . . , pk}에서 생성한 오퍼레이션 집합으로 각 오퍼레이션은 걸리지(stuck) 않고 명령 시퀀스 <cmd1; … ;cmd n>를 축소(reduce)한다.
축소(reduction)는 모든 전제 조건이 충족되는 규칙의 적용이 없으면 걸리게 된다. 예를 들어, idx(n)가 리스트의 끝을 지나 반복문 수행하면, 그림 9의 IDX3, 4 규칙은 멈추는데, 이는 n이 리스트의 삭제되지 않은 요소의 수보다 크면 발생한다. 실제 구현에서는 런타임 오류가 발생한다. 멈추지 않는 실행에 대해 유효한 실행을 제한함으로써 오퍼레이션이 실제로 존재하는 리스트 요소만 참조하도록 한다.
yield 명령을 호출하지 않기 때문에(또는 yield의 비결정적 실행이 RECV 규칙을 적용하지 않기 때문에) 실행이 네트워크 통신을 절대로 수행하지 않는 것이 유효하다. 축소가 멈추는 지 여부를 결정하기 위해 복제본의 로컬 상태만 필요로 한다.

정의 2 (히스토리). 히스토리(history)는 APPLY-LOCAL 및 APPLY-REMOTE 규칙을 적용하여 특정 복제본 p에 적용된 순서대로 일련의 작업이다.
평가 규칙은 주어진 복제본에서 한 번에 하나의 오퍼레이션을 순차적으로 적용하므로 순서가 잘 정의된다. 2개의 복제본 p, q가 동일한 오퍼레이션 집합을 적용한다고 할지라도, 즉 Ap(ops) = Aq(ops)인 경우, 그들은 상이한 순서로 임의의 동시 오퍼레이션을 적용 할 수 있다. APPLY-REMOTE의 전제 op.deps ⊆ Ap(ops)로 인해, 히스토리는 인과 관계와 일치한다. 오퍼레이션에 인과 관계가 있는 경우, 히스토리의 종속성 이후 특정 위치에 존재한다.

정의 3 (문서 상태). 복제본 p의 문서 상태는 문서를 포함한 Ap의 하위 트리이다(Ap(mapT(doc)) 또는 Ap (listT(doc)) 또는 Ap(regT(doc))).
Ap는 let으로 정의한 변수를 포함하는데, 이는 하나의 복제본에 대해 로컬이며 복제 된 상태의 일부가 아니다. 문서 상태의 정의는 이러한 변수를 제외한다.
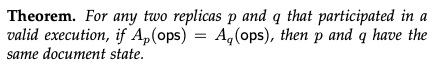
정리. 유효한 실행에 참여한 두 개의 복제본 p와 q에 대해 Ap (ops) = Aq (ops)이면 p와 q는 동일한 문서 상태를 갖는다.
이 정리는 부록에서 증명한다. 이것은 수렴의 안전성을 공식화한다. 두 개의 복제본이 동일한 순서의 오퍼레이션을 다른 순서로 처리 한 경우 동일한 상태로 수렴한다. 활성 속성(aliveness)과 함께, 모든 복제본이 결국 모든 오퍼레이션을 처리하므로 원하는 수렴 개념을 얻는디. 모든 복제본은 결국 동일한 상태로 끝난다.
활성 속성은 충분히 자주 yeild를 호출하는 복제본의 가정과 공정하게 선택되는 yeild에 대한 모든 비결정적 규칙에 따라 달라진다. 이 논문에서 활성 속성을 공식화하지 않지만, 일반적으로 네트워크 중단은 유한한 기간이기 때문에 실제로는 적용될 수 있다고 주장한다.
5. 결론, 향후 작업
이 논문에서는 JSON 데이터 모델을 사용하여 리스트, 맵 및 레지스터의 중첩 CRDT를 작성하는 방법을 설명했다. 임의로 중첩 된 리스트, 맵을 지원하며 복제본이 네트워크 통신을 기다리지 않고 데이터를 임의로 변경할 수 있다. 복제본은 비동기적 조작의 형태로 다른 복제본에 변형을 전송한다. 동시 오퍼레이션은 교환 가능(commutative)하므로 애플리케이션 별 충돌 해결 로직이 없어도 복제본이 동일한 상태로 수렴 된다.
이 논문은 JSON CRDT의 형식 의미론에 중점을 두고 수학적 모델로 표현했다. 우리는 알고리즘의 실제 구현을 위해 작업 중이며 후속 작업에서 성능 특성을 보고 할 예정이다.
동시 수정으로 인해 입력을 잃지 않는 원칙은 처음에는 합리적이라고 판단되었지만 그림 6에서 볼 수 있듯이 순차 프로그램에 익숙한 애플리케이션 프로그래머에게는 문제(suprising) 상태가 되기도 한다. 애플리케이션 프로그래머의 기대치를 이해하고 동시에 수정하는 경우에는 데이터 구조를 설계하기 위해서는 더 많은 작업이 필요하다. 더 복잡한 애플리케이션을 지원하려면 스키마 언어가 필요할 것이다. 스키마 언어는 숫자가 레지스터가 아닌 카운터로 취급 되어야한다는 의미와 같은 의미론적 주석이 필요할 수도 있다.
이 논문에서 정의 된 CRDT는 삽입, 삭제 및 할당 작업을 지원한다. 이 외에도 이동 오퍼레이션(순서가 지정된 목록에서 요소의 순서를 변경하거나 문서의 한 위치에서 다른 위치로 하위 트리를 이동) 및 실행/취소 오퍼레이션을 지원하는 것이 유용할 것이다. 또한 데이터 구조의 무한한 확장을 막기 위해 쓰레기 수집(garbage collection, tombstone 제거)이 필요하다.
향후 작업에서 이러한 누락 된 기능을 해결할 계획이다.
(Appendix 생략… 어려워서…)