Google Docs 같은 실시간 협업 에디터를 만드는 방법
실시간 협업 애플리케이션
이제는 실시간 협업 애플리케이션이 많은 사용자에게 익숙하다. 대표적인 예로는 Google Docs가 있다. Google Docs는 동시에 여러 명의 사용자가 문서 하나를 수정할 수 있다. 각자 수정하는 문서를 메일로 서로 주고받고 취합할 필요가 없으니 매우 편리하다. 다수의 사람이 동시에 편집해도 결과적으로 문서의 내용은 같아진다. 이런 특징을 Convergence(수렴)라고 부른다.
실시간 협업 애플리케이션의 구조 (Optimistic replication)
Google Docs와 같은 실시간 협업 애플리케이션의 구조는 Git과 유사하다. 우리는 Git을 사용할 때, 먼저 Local 저장소에 작업한 변경사항을 Commit하고 시간이 흐른 뒤 어느 정도 작업이 완료되면 다른 동료에게 작업한 내용을 공유하기 위해서 Commit을 Remote 저장소에 Push한다. 하지만 Git에서는 Remote 저장소에 먼저 추가된 또 다른 Commit이 있을 때, 해당 브렌치를 Pull한 뒤 Merge conflict가 발생하면 이를 손으로 직접 해결한다.
이런 스타일의 복제 전략을 취한 시스템을 Optimistic replication system이라고 부르는데, Optimistic replication은 복제본의 내용이 잠시 달라지는 것을 허용하는 복제 전략이다. Optimistic replication system의 구조는 아래와 같은 그림으로 표현할 수 있다.
[사용자 A] -> [사용자 A의 복제본] <- (Operations) -> [사용자 B의 복제본] <- [사용자 B]
사용자 A는 로컬에서 복제본(Replica)을 먼저 직접 편집하고 같은 문서를 열고 있는 사용자 B의 복제본과 동기화하기 위해서 나중에 로컬 변경사항(Operation)을 전송한다.
Google Docs에서는 백그라운드에서 이런 종류의 변경사항을 지속해서 전송한다. (5G나 Google Stadia를 보면 미래에는 모르겠지만) 여기에서는 네트워크 지연시간을 고려해야 하는데, 사용자가 편집할 때 변경사항을 전송하고 응답받은 뒤 문서를 업데이트해서 화면에 그리면 사용자는 느리다고 느낄 것이다. 그래서 Google Docs에서는 사용자가 텍스트를 타이핑하면 즉시 변경사항을 로컬 메모리에 있는 복제본에 먼저 반영한 뒤 화면에 표현하고 이후에 비동기적으로 변경사항을 원격지의 복제본에 반영한다. 이 구조 때문에 편집하고 있는 화면에 변경사항이 지연 없이 바로 반영된다.
실시간 협업 애플리케이션의 동작 방식 (Eventual consistency)
이렇게 한 노드가 다른 노드의 편집과 상관없이 독립적으로 먼저 로컬 데이터를 수정하고 나중에 원격지에 다른 노드와 데이터를 동기화한다면, 동시성 문제를 생각해야 한다. 특히 한 노드가 시스템의 다른 노드와 단절되는 네트워크 파티션이 발생하거나 오프라인 상태에서는 이 문제는 더 분명히 드러난다. 사용자는 메모리에 저장된 문서의 로컬 복제본을 계속해서 편집하고 있지만, 인터넷 연결이 끊어져서 변경사항을 다른 사용자에게 전송할 수 없게 된다. 이 상황에는 우선 로컬 복제본을 계속해서 편집하고 사용자의 화면에 반영해서 프로그램이 잘 동작하는 것처럼 보이게 하고 나중에 네트워크가 복구되면 로컬에 쌓아둔 변경사항을 원격지의 다른 사용자에게 전송한다. 이럴 때도 각자 수정하고 있는 문서가 충돌 없이 병합되어야 한다.
협업 텍스트 에디터의 예를 들면 아래와 같은 상황을 생각해볼 수 있다.
초기상태: "안녕."
~~ 네트워크 단절 ~~
사용자 A: "안녕 Summernote."
사용자 B: "안녕. (^_^)"
~~ 네트워크 복구 ~~
결과상태: "안녕 Summernote. (^_^)"
Git에서는 이런 상황에 Merge Conflict가 발생해서 수동으로 충돌을 수정해야 하지만 Google Docs에서는 충돌을 해결하는 팝업 같은 게 나오지는 않는다. Google Docs가 이 충돌을 자동으로 해결하기 때문에 여러 사용자가 하나의 문서를 실시간으로 함께 편집할 수 있다.
위 예제를 자세히 살펴보면, 사용자 A는 “안녕”과 “.” 사이에 “Summernote”라는 텍스트를 입력했고 사용자 B는 “.” 뒤에 “ (^_^)”를 입력했는데, 결과적으로 데이터가 같아진다. 특정 시점에는 내용이 서로 달랐지만, 결과적으로 같아지는 이런 스타일의 Consistency Model을 Eventual consistency라고 부른다. 동기화 시에 두 사용자의 텍스트 삽입 의도가 모두 반영되어 있으므로 결과상태가 적절해 보인다.
분산 시스템에는 Consul, Zookeeper 같은 애플리케이션에서 사용하는 노드 간에 합의를 위한 Paxos, Raft 같은 Consensus 알고리즘도 있는데, 겉보기에는 협업 애플리케이션과 구조가 유사해 보이지만 해결하고 있는 문제는 매우 다르다. 네트워크 파티션 상황에 Consensus 알고리즘이 하나가 선택되고 나머지가 취소되어 버려지는 반면에, 협업 애플리케이션의 알고리즘은 여러 사용자의 의도를 모두 반영하면서 병합(Merge)한다.
Operation 디자인하기
우리가 개발하고 있는 애플리케이션은 데이터를 Counter, Text, Set, Hashtable, JSON등 다양한 데이터타입으로 표현한다. 먼저 가장 간단한 카운터를 대상으로 변경사항인 Operation을 디자인해보자.
초기상태: 1
~~ 네트워크 단절 ~~
사용자 A: 1 (+1) = 2 // Increase(1)
사용자 B: 1 (+2) = 3 // Increase(2)
~~ 네트워크 복구 ~~
기대하는 결과상태: 1 (+1) (+2) = 4
사용자 A: 2 (+2) = 4 // 사용자 B의 Increase(2) 반영
사용자 B: 3 (+1) = 4 // 사용자 A의 Increase(1) 반영
위 예제를 자세히 살펴보면, 사용자 A는 초기상태 1에 1을 더해서 2가 되었고 사용자 B는 1에 2을 더해서 3라는 결과를 화면에서 보았다. 이 상황을 동기화했을 때, 2나 3으로 끝내지 않고 두 사용자의 Increment 의도를 모두 반영해서 4이라는 결과상태로 마무리하는 것이 적절해 보인다.
Operation을 디자인할 때 고려할 것 (Convergence 문제)
이렇게 충돌을 자동으로 해결하는 시스템을 디자인할 때, 조금 더 생각해볼 문제가 있는데, 다시 텍스트 예제로 돌아가보자.
초기상태: "안녕."
~~ 네트워크 단절 ~~
사용자 A: "안녕 Summernote." // Insert(2, " Summernote.")
사용자 B: "안녕. (^_^)" // Insert(3, " (^_^)")
~~ 네트워크 복구 ~~
기대한 결과상태: "안녕 Summernote. (^_^)"
사용자 A: "안녕 (^_^)Summernote." // 사용자 B의 Operation Insert(3, " (^_^)") 반영
사용자 B: "안녕 Summernote. (^_^)" // 사용자 A의 Operation Insert(2, "Summernote.") 반영
위 예제에서는 Integer Index를 이용해서 Insert Operation을 디자인 했는데, 사용자 A와 사용자 B가 네트워크가 복구한 뒤에 각자의 변경사항을 반영한 결과가 서로 달라질 수 있는 경우를 볼 수 있다. Increase Operation 경우 교환 법칙(commutative property)을 만족하지만, 위에 디자인한 Insert Operation은 만족하지 않는다. 이런 경우 문서의 상태가 갈라져서(divergence) 전체 문서를 주고 받지 않는 이상 다시는 동기화할 수 없게 된다.
Convergence(수렴) 문제를 해결하는 방법들
지금까지 실시간 협업 애플리케이션의 구조와 이런 시스템을 디자인할 때 해결해야 하는 문제에 대해 알아봤다. 이런 수렴 문제를 해결할 수 있는 알고리즘의 큰 분류에는 OT(Operational Transformation)와 CRDT(Conflict-free replicated data type)가 있다. 사실 OT의 한 알고리즘이 Google Docs 내부에 사용된다. 수렴 문제를 해결하는 알고리즘을 설계하는 것은 어려운 일인데, 일부 OT 알고리즘은 논문 발표 이후에 수렴을 만족하지 못한다는 것이 알려지기도 했다.
그리고 이 수렴 문제를 데이터 타입에 추상화해서 간단히 한 CRDT가 있다. CRDT 위키백과에서 다양한 데이터타입들, 카운터 타입인 G-Counter, PN-Counter, 셋 타입인 G-Set, 2P-Set, 리스트 타입인 RGA등 다양한 데이터타입을 볼 수 있다. CRDT도 특징에 따라 Operation-based CRDTs와 State-based CRDTs로 나뉘는데, 이 중 Operation-based CRDT는 교환 법칙의 특성을 활용해서 Concurrent 수정의 Operation의 경우 순서가 뒤바뀌어서 실행되어도 동일한 결과 상태가 나오도록 하는 전략을 취한다.
다음 챕터에는 실시간 협업 에디터를 구현할 수 있는 RGATreeSplit에 대해 알아보는데, 이 데이터타입은 Operation-based CRDTs의 한 종류이다.
실시간 협업 에디터를 구현할 수 있는 데이터 타입
먼저 텍스트 에디터의 텍스트를 표현할 수 있는 RGA에 대해서 알아보자.
LinkedList
동작 원리를 간단히 알아보기 위해서 텍스트를 문자(Character)를 원소로 가진 연결형 리스트라고 생각해보자.
["안"] -> ["녕"]
“안녕”이라는 문자열을 예로들면 위와 같은 리스트라고 생각해 볼 수 있다.
초기상태: ["안"] -> ["녕"]
~~ 네트워크 단절 ~~
사용자 A: ["안"] -> ["녕"] -> ["."]
사용자 B: ["방"] -> ["갑"] -> ["안"] -> ["녕"]
~~ 네트워크 복구 ~~
결과상태: ["방"] -> ["갑"] -> ["안"] -> ["녕"] -> ["."]
위 같은 편집의 경우 커서를 서로 다른 위치에 두고 사용자 A는 “안녕” 뒤에 “.”를 입력했고 사용자 B는 “안녕” 앞에 “방갑”을 입력했기 때문에 결과상태에 문제가 없다.
초기상태: ["안"] -> ["녕"]
~~ 네트워크 단절 ~~
사용자 A: ["안"] -> ["녕"] -> ["."]
사용자 B: ["안"] -> ["녕"] -> ["!"]
~~ 네트워크 복구 ~~
결과상태: ["안"] -> ["녕"] -> ["."] -> ["!"] // ["."]와 ["!"]의 순서를 결정해야 함
하지만 두 번째 예제의 경우 같은 위치인 ["녕"] 뒤에 사용자 A, B가 값을 입력한다면 사용자 A의 ["."]와 사용자 B의 ["!"]의 순서를 결정해야 한다. 그래서 순서를 결정할 수 있는 장치가 필요하다. 이를 RGA에서는 분산 시스템에서 사용하는 논리시계를 이용해서 처리했다.
Logical Clock
분산 시스템에서 각 노드의 시계를 정확하게 똑같이 동기화하는 건 매우 어려운 문제이다. 특정 시간을 노드에 전송해서 동기화하려고 해도 이 전송에 지연시간이 발생하고 각각이 정확히 얼마나 걸릴지 모르기 때문이다. 또 물리 시계를 정확하게 똑같이 동기화 할 수 있다고 하더라도 동일한 시간에 발생한 이벤트의 순서를 결정해야 했다. 분산 시스템에는 이런 문제를 해결할 수 있는 Lamport clock과 같은 논리시계가 있는데, 시스템 내에 발생한 이벤트들을 시스템 내부 전체에서 유일한 순서(Total order)를 정의할 수 있다.
여기에서는 대표적인 논리시계인 Lamport clock을 활용해서 이벤트의 순서를 정하는 방법에 대해 알아본다.

출처: “멀티 디바이스 동기화 플랫폼과 분산시스템의 기초” - 노현걸
가장 우측 그림은 노드 1, 2가 있을 때, 발생할 수 있는 이벤트의 예를 보여준다. 가장 좌측 그림의 실선은 인과(Casual) 관계, 점선은 Concurrent 관계를 표현했다. 가운데 그림은 이 이벤트 들의 Total Order를 보여준다.
public int compare(Clock clockA, Clock clockB) {
int compare = Integer.compare(clockA.timestamp, clockB.timestamp);
if (compare != 0) return compare;
return Integer.compare(clockA.nodeId, clockB.nodeId);
}
논리 시계인 Clock이 timestamp와 nodeId를 갖고 있다고 가정하면 분산 시스템 내에서 발생한 전체 이벤트의 순서를 위 함수로 알아낼 수 있다.
RGA: LinkedList + Logical Clock
이런 논리 시계를 도입 했다고 가정하면 이전 데이터를 다음과 같이 표현할 수 있다.
반영 전: ["안"] -> ["녕"]
반영 후: [T1-A: "안"] -> [T2-A: "녕"]
요소(Element)에 값 외에 논리 시계가 추가되었는데, 이 논리 시계는 요소를 삽입한 논리적 시간을 나타낸다.
초기상태: [T1-A: "안"] -> [T2-A: "녕"]
~~ 네트워크 단절 ~~
사용자 A: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."]
사용자 B: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-B:"!"]
~~ 네트워크 복구 ~~
결과상태: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."] -> [T3-B:"!"]
같은 위치인 ["녕"] 뒤에 사용자 A, B가 값을 입력했지만, 사용자 A의 ["."]와 사용자 B의 ["!"]의 순서를 비교했을 때, 논리시계를 사용하므로 순서를 정할 수 있는데, 여기서는 T3-A가 T3-B보다 앞선다고 가정하고 결과상태처럼 둘의 순서를 결정할 수 있다. 위 예제처럼 CRDT는 데이터를 표현하는 값외에 논리시계나 삭제를 표시하는 Tombstone과 같은 메타(Meta)가 더 포함된다.
초기상태: [T1-A: "안"] -> [T2-A: "녕"]
~~ 네트워크 단절 ~~
사용자 A: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."] // InsertAfter(T3-A, T2-A, ".")
사용자 B: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-B:"!"] // InsertAfter(T3-B, T2-A, "!")
~~ 네트워크 복구 ~~
기대한 결과상태: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."] -> [T3-B:"!"]
사용자 A: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."] -> [T3-B:"!"] // 사용자 B의 Operation InsertAfter(T3-B, T2-A, "!") 반영
사용자 B: [T1-A:"안"] -> [T2-A:"녕"] -> [T3-A:"."] -> [T3-B:"!"] // 사용자 A의 Operation InsertAfter(T3-A, T2-A, ".") 반영
RGA는 요소의 ID로 논리 시계를 사용하는 리스트형 자료 구조라 생각할 수 있다.
RGATreeSplit
지금까지 알아본 RGA를 Text로 사용할 때 성능을 개선할 수 있는 포인트가 더 있는데, 로컬 실행 복잡도나 공간 복잡도를 개선한 버전이 RGATreeSplit이다. RGATreeSplit은 Apache commons에 있는 TreeList처럼 LinkedList 대신 Tree 구조를 도입해서 로컬 실행시간을 개선하고 각 요소에 문자가 아닌 문자열을 보관해서 공간을 작게 사용한다.
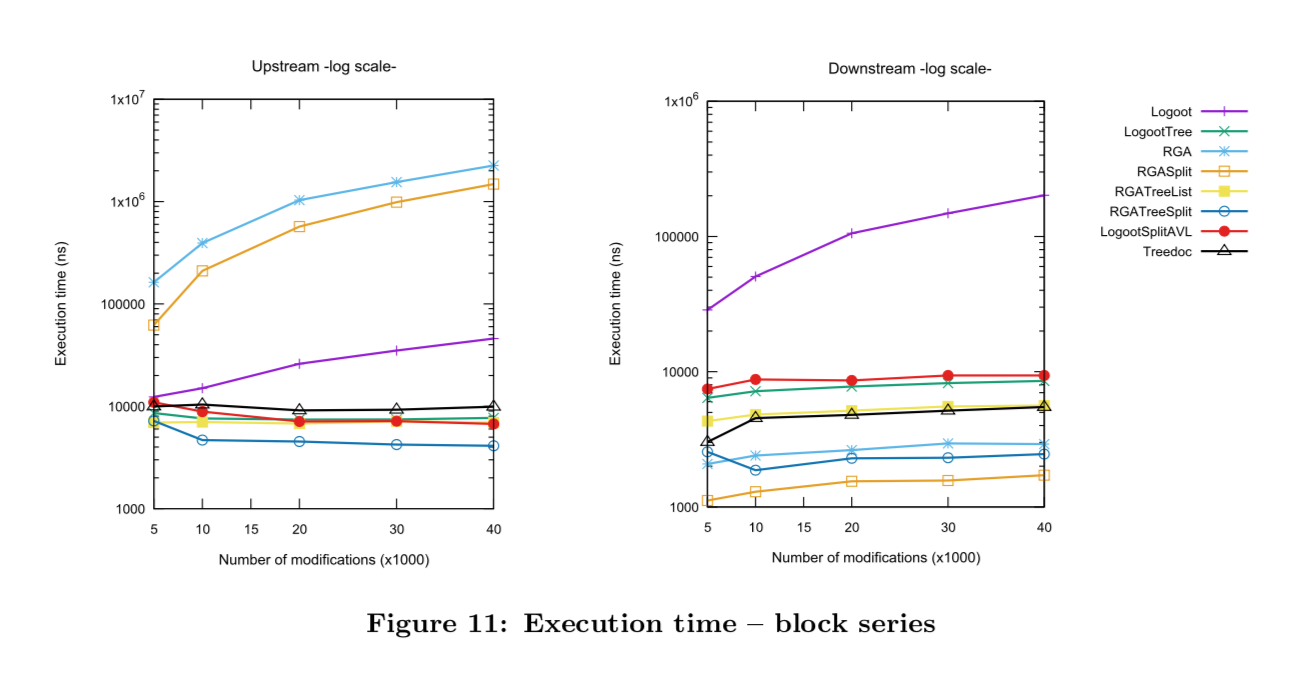 출처: rgasplit-group2016-11.pdf
출처: rgasplit-group2016-11.pdf
좌측 Upstream은 Local에서 편집 실행시간, 우측 Downstream은 Remote에서 편집 실행시간을 뜻한다. Execution time이 낮을 수록 성능이 좋다.
마무리
지금까지 Google Docs와 같은 실시간 협업 애플리케이션의 구조에 대해 간략히 살펴보고 실시간 협업 에디터를 구현하는데, 사용할 수 있는 CRDT 데이터타입인 RGATreeSplit에 대해 알아봤다.
CRDT는 협업 애플리케이션 뿐 아니라 지역적으로 떨어진 IDC 간에 DB를 Master-Master로 운영하는 Geo Distribution DB 시스템에도 활용된다(Redis Enterprise, Azure Cosmos DB).
CRDT는 Facebook 규모의 Like Counter라든지 캐시등 다양한 형식으로도 활용할 수 있어 보인다.