DB를 이용한 Pagination
게시판 만들기
대학 4학년 때쯤, 직업으로 개발자가 되고 싶었다. 영상 처리 랩에서 학부생으로 얼굴 인식(Face detection) 관련 논문을 읽고 MATLAB으로 코딩하는 일을 하며 용돈을 벌었지만 막막했다. 간단한 웹페이지도 만들 줄 몰랐고 이대로는 안 되겠다고 생각되어서 학원에 등록했고 거기서 DB를 이용한 Pagination에 대해 배웠다. 얼마 지나지 않아서 다행히 취업했는데, 당시에는 결국 개발자가 될 수 있었던 이유는 얼굴 인식이 아닌 게시판을 만들 수 있기 때문이라고 생각했다.
최근 회사 프로젝트에서 분 단위의 슬로우 쿼리가 발생했는데, 레거시 코드에서 학원에서 처음 배웠던 방식의 DB Pagination을 발견했다. 해당 MongoDB Collection에는 약 74,380,000개의 Document가 저장되어 있었다. 아마도 원작자는 Admin 페이지이기도 했고 많은 Document가 삽입될 줄은 몰랐던 거 같다.
DBA로 일하거나 DB를 직접 만들어 본 경험은 없어서 자세히 알지는 못하지만 아는 만큼이라도 DB Pagination에 대해서 적어보고 싶었다.
OFFSET, LIMIT
레거시 코드는 Pagination에 OFFSET, LIMIT을 사용했다.
-- 페이지 크기가 10일 때, P 번째 페이지의 포스트 리스트 가져오기
SELECT * FROM posts OFFSET P * 10 LIMIT 10 ORDER BY published_at;
OFFSET는 쿼리의 처음 N 개의 결과를 건너뛰도록 한다. LIMIT는 SELECT에 의해 반환된 결과 수를 제한하는 데 사용한다. 두 번째 페이지(P = 1)의 쿼리를 그림으로 표현하면 아래와 같다.
OFFSET LIMIT 남은 포스트들
___||___ ___||___ __||__
/ \ / \ /
RRRRRRRRRR RRRRRRRRRR RRRRRRRRRR...
\________/
||
현재 페이지의 포스트들
포스트가 많아질 때를 고려해서 Index 생성한다. 발행 일자를 기준으로 노출하기 위해서 ORDER BY를 사용하고 있는데, 쿼리 실행 시에 published_at 필드의 값으로 정렬하는데 비용이 발생한다. 따라서 published_at 필드에 Index를 만든다. 하지만 Index를 만든 뒤에도 페이지 번호인 P 값이 커질수록 점점 느려진다. 이 문제는 DB Index의 구조와 관련 있다.
정렬된 파일에서 Binary search로 찾는 시간
먼저 정렬된 파일에서 특정 아이템을 Binary search로 찾는 데 걸리는 시간에 대해서 생각해보자. Binary search는 정렬된 목록에서 특정 아이템을 \(log_2(n)\)에 찾아낸다. 예를 들어 테이블에 1,000,000개의 레코드가 있다면 20번 이내의 비교로 찾아낸다(\(log_2(1,000,000) = 20\)).
전통적으로 DB는 데이터를 디스크에 저장한다. 디스크의 읽기 시간은 키를 비교 시간보다 훨씬 오래 걸리는데, 이 읽기 시간에 디스크의 Seek time과 Rotational delay가 포함된다. 계산을 간단히 하기 위해서 1회 읽기 시간에 10ms 걸린다고 가정하고 1,000,000개의 레코드가 저장된 테이블에서 하나의 레코드를 찾는 데 걸리는 시간은 20회의 디스크 읽기를 수행하므로 대략 0.2s이다.
B+tree Index
DB Index의 대표적인 타입은 B+tree 기반이다. B+tree는 데이터가 메모리가 아닌 디스크에 저장되어 있을 때, Binary search tree(이하 BST)에 비해 효율적이다. B+tree는 다른 BST에 비해서 fanout 크기가 크고 디스크 I/O 수가 작게 동작하도록 설계되어 있다. 또 B+tree의 리프 노드(Leaf node)는 서로 연결되어 있어서 순차 처리가 가능하므로 Range search에 유리하다.
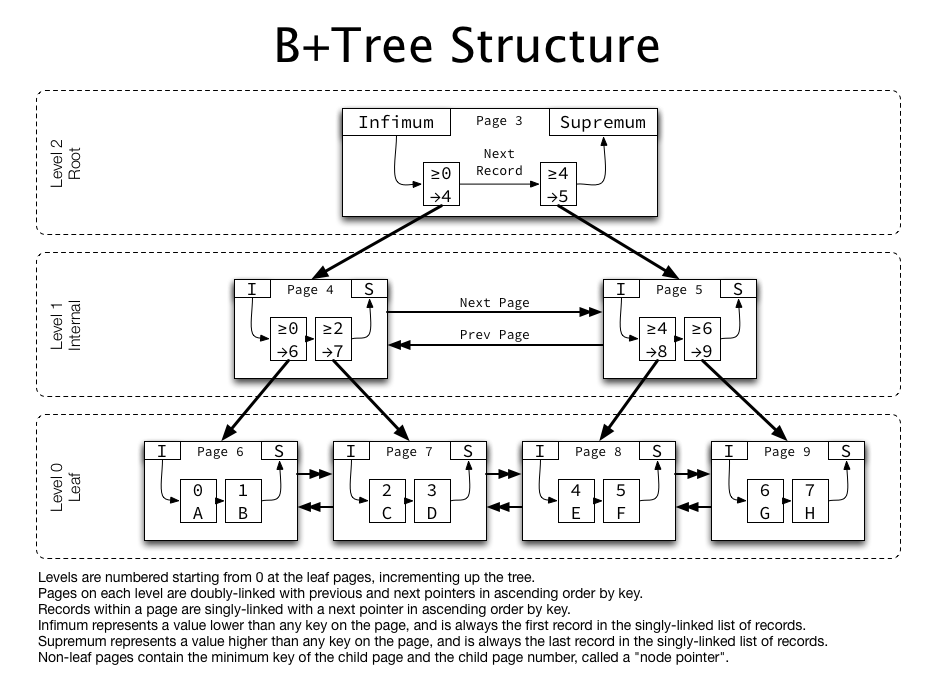
출처: https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
Index의 실제 동작은 복잡하지만 여기서는 원리만 파악하기 위해서 Range search에 대해 간략히 알아본다.
SELECT * FROM posts WHERE 1 <= key AND key <= 10;
key가 B+tree Index로 색인되어 있을 때 위 쿼리의 동작은 다음과 같다. 먼저 루트 노드에서 리프 노드로 내려가면서 하위 key인 1을 찾는다(\(O(log_b(n))\)). 그리고 하위 key인 1에서 상위 key인 10을 찾을 때까지 리프 노드에서 순차적으로 리스트를 순회하며 레코드를 읽는다(\(O(k)\)). 따라서 B+tree Index을 이용한 k개 아이템의 Range search의 시간 복잡도는 \(O(log_b(n)+k)\)이다.
이전에 알아본 DB Pagination의 OFFSET은 순차 탐색에 해당된다(\(O(k)\)). 따라서 페이지 번호가 커질 때마다 OFFSET의 값이 커지므로 실행 시간이 선형으로 증가한다(\(OFFSET = PAGE\_NO \times PAGE\_SIZE\)).
OFFSET 없는 Pagination
OFFSET 성능 문제를 회피하기 위해서 순서가 있는 key(e.g AUTO_INCREMENT PRIMARY KEY) 기반으로 Pagination을 디자인한다.
-- 페이지 크기가 10일 때, offset_key 포스트의 다음 페이지 리스트 가져오기
SELECT * FROM posts WHERE key > offset_key LIMIT 10;
그림으로 표현하면 다음과 같다.
offset_key LIMIT 남은 포스트들
| ___||___ __||__
| / \ /
RRRRRRRRRR RRRRRRRRRR RRRRRRRRRR...
\________/
||
현재 페이지의 포스트들
페이지의 시작 포스트를 OFFSET이 아닌 key로 찾고 있고 페이지의 크기가 일정하기 때문에, 페이지 번호가 커질 수록 실행 시간이 선형으로 증가하는 일은 발생하지 않는다 \(O(log(n))\).
사용자가 임시 저장한 포스트를 발행할 때에는 published_at만 업데이트하면 안되고 새로운 key를 발급받은 포스트를 추가하도록 애플리케이션 코드를 변경해야 한다.
LIKE
레거시 코드는 특정 문자가 포함된 포스트를 찾기 위해서 LIKE를 사용한다. 문자열 "맛집"이 제목에 포함된 포스트의 Pagination 쿼리는 다음과 같다.
-- 페이지 크기가 10일 때, I 번째 페이지의 포스트 리스트 가져오기
SELECT * FROM posts WHERE title LIKE '%맛집%' OFFSET I * 10 LIMIT 10;
여기서 title 필드의 Index가 있더라도 문제가 발생하는데, 이는 B+tree 기반 Index에서 해당 단어를 왼쪽부터 오른쪽으로 찾기 때문이다. 따라서 B+tree Index는 적합하지 않다.
해결 방법을 몇 가지를 생각해봐야 하는데, 먼저 스펙 축소가 있다. 특정 키워드가 “포함된”을 “시작하는”으로 변경하는 것이다. WHERE 뒤 LIKE '%맛집%'를 LIKE '맛집%'로 변경한다. 스펙 변경이 어렵다면 Full text search 타입 Index로 title을 색인한다.
마무리
게시판 만들기는 개발을 배우는 데 좋은 주제였다. 조금씩은 달랐지만 지금도 종종 DB에 데이터를 저장하고 목록을 불러오는 작업을 하고 있다. 데이터가 많아지면, 내부를 대략이라도 알 필요가 있다고 생각한다.