DLS Course 1 - Week 1
Welcome to the Deep Learning Specialization
Courses in this sequence
- Neural Networks and Deep Learning
- Improving Deep Neural Networks: Hyper-parameter tuning, Regularization and Optimization
- Structuring your Machine Learning project
- Convolutional Neural Networks(CNN)
- Natural Language Processing: Building sequence models(RNN, LSTM)
Introduction to deep learning
What is neural network?
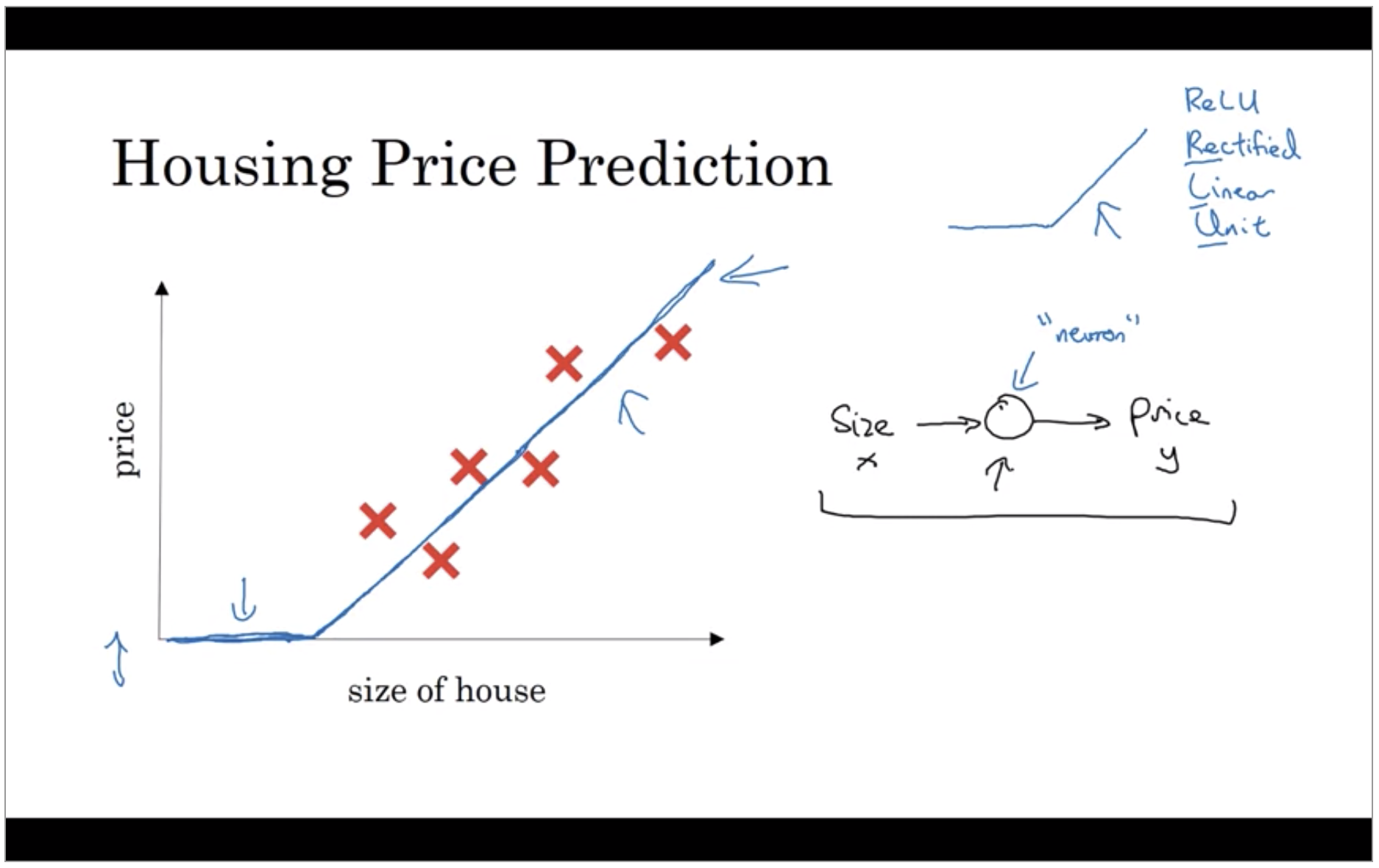
Let’s say you have a data sets with six houses, so you know the size of the houses in square feet or square meters and you know the price of the house and you want to fit a function to predict the price of the houses, the function of the size.
We know that prices can never be negative, right. So instead of the straight line fit which eventually will become negative. So you can think of this function that you’ve just fit the housing prices as a very simple neural network. This function is called a ReLU function which stands for rectified linear units.
We have as the input to the neural network the size of a house which one we call x. It goes into this node, this little circle and then it outputs the price which we call y. So this little circle, which is a single neuron in a neural network, implements this function that we drew on the left. And all the neuron does is it inputs the size, computes this linear function, takes a max of zero, and then outputs the estimated price.
So if this is a single neuron, neural network, really a tiny little neural network, a larger neural network is then formed by taking many of the single neurons and stacking them together. So, if you think of this neuron that’s being like a single Lego brick, you then get a bigger neural network by stacking together many of these Lego bricks.
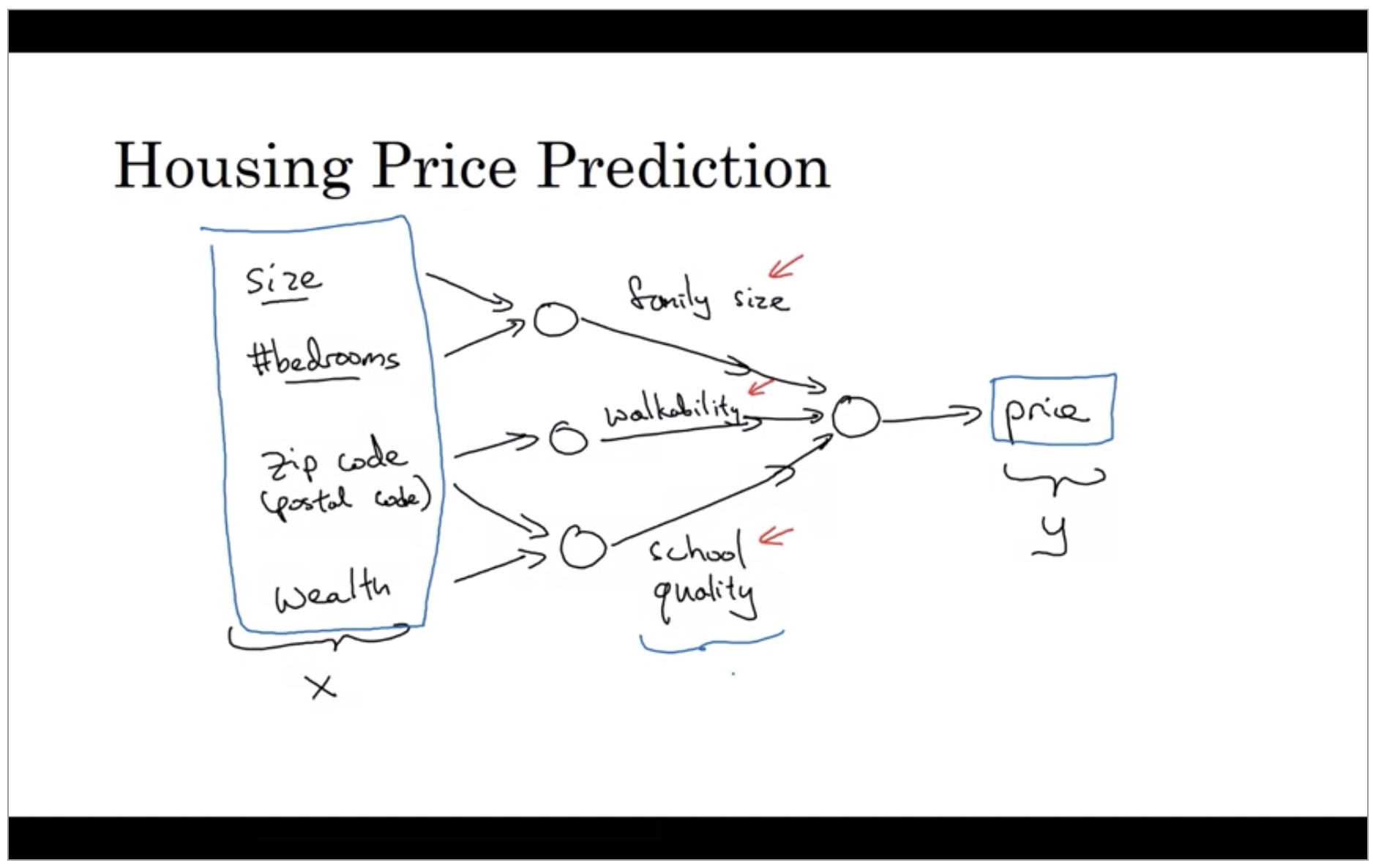
Let’s say that instead of predicting the price of a house just from the size, you now have other features. You know other things about the host, such as the number of bedrooms. One of the things that really affects the price of a house is family size. And it’s really based on the size in square feet or square meters, and the number of bedrooms that determines whether or not a house can fit your family’s family size.
And then maybe you know the zip codes, in different countries it’s called a postal code of a house. And the zip code maybe as a future to tells you, walkability. Thing just walks the grocery store? Walk the school? Do you need to drive? Postal code tells you how good is the school quality.
In this case family size, walkability, and school quality and that helps you predict the price. So in the example x is all of these four inputs. And y is the price you’re trying to predict.
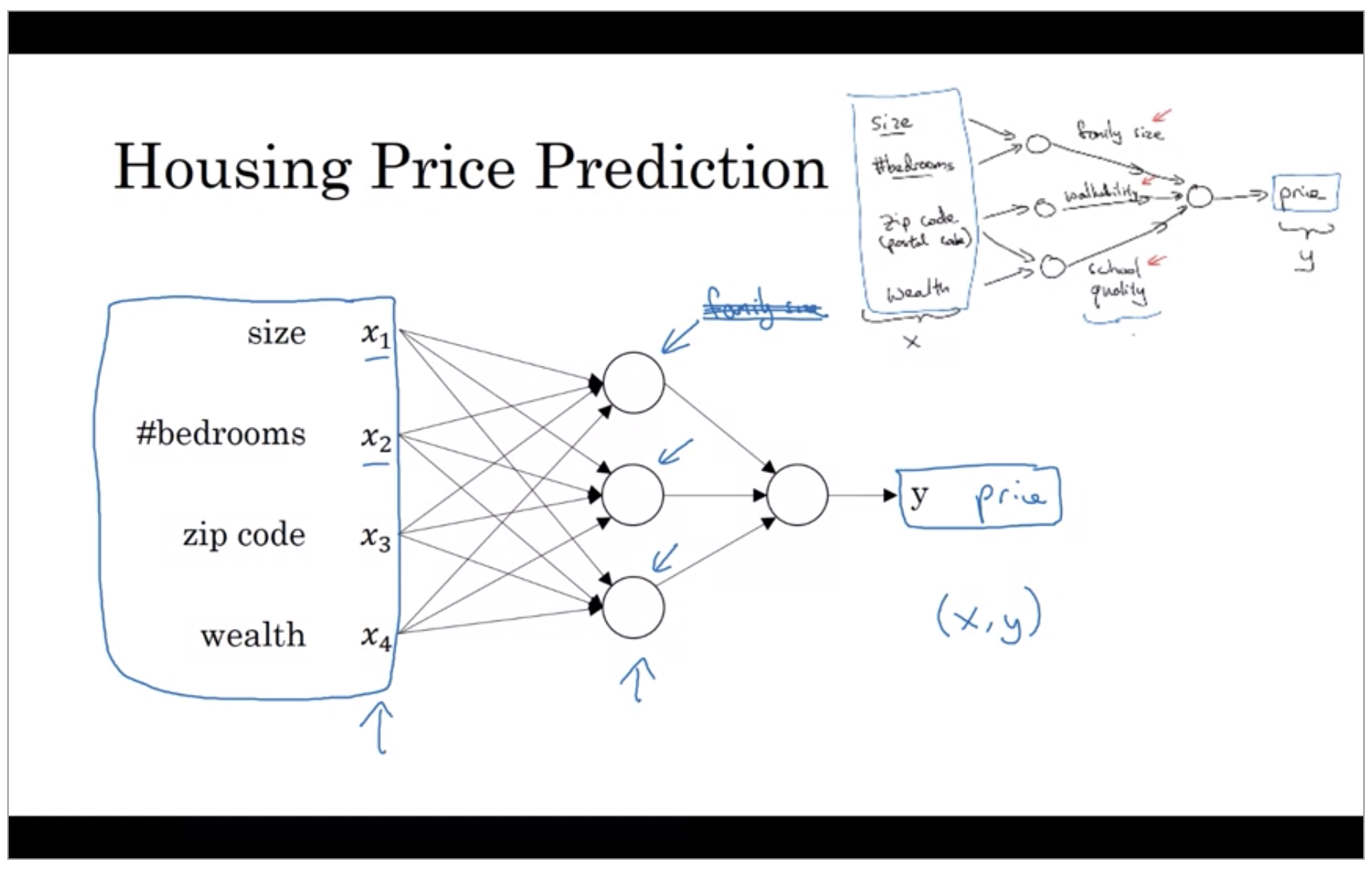
So what you actually implement is this. Where, here, you have a neural network with four inputs. So the input features might be the size, number of bedrooms, the zip code or postal code, and the wealth of the neighborhood. And so given these input features, the job of the neural network will be to predict the price y.
And notice also that each of these circle, these are called hidden units in the neural network, that each of them takes its inputs all four input features. Rather than saying these first nodes represent family size and family size depends only on the features X1 and X2. Instead, we’re going to say, well neural network, you decide whatever you want this known to be.
And the remarkable thing about neural networks is that, given enough data about x and y, given enough training examples with both x and y, neural networks are remarkably good at figuring out functions that accurately map from x to y.
Supervised Learning with Neural Networks
In supervised learning, you have some input x, and you want to learn a function mapping to some output y.
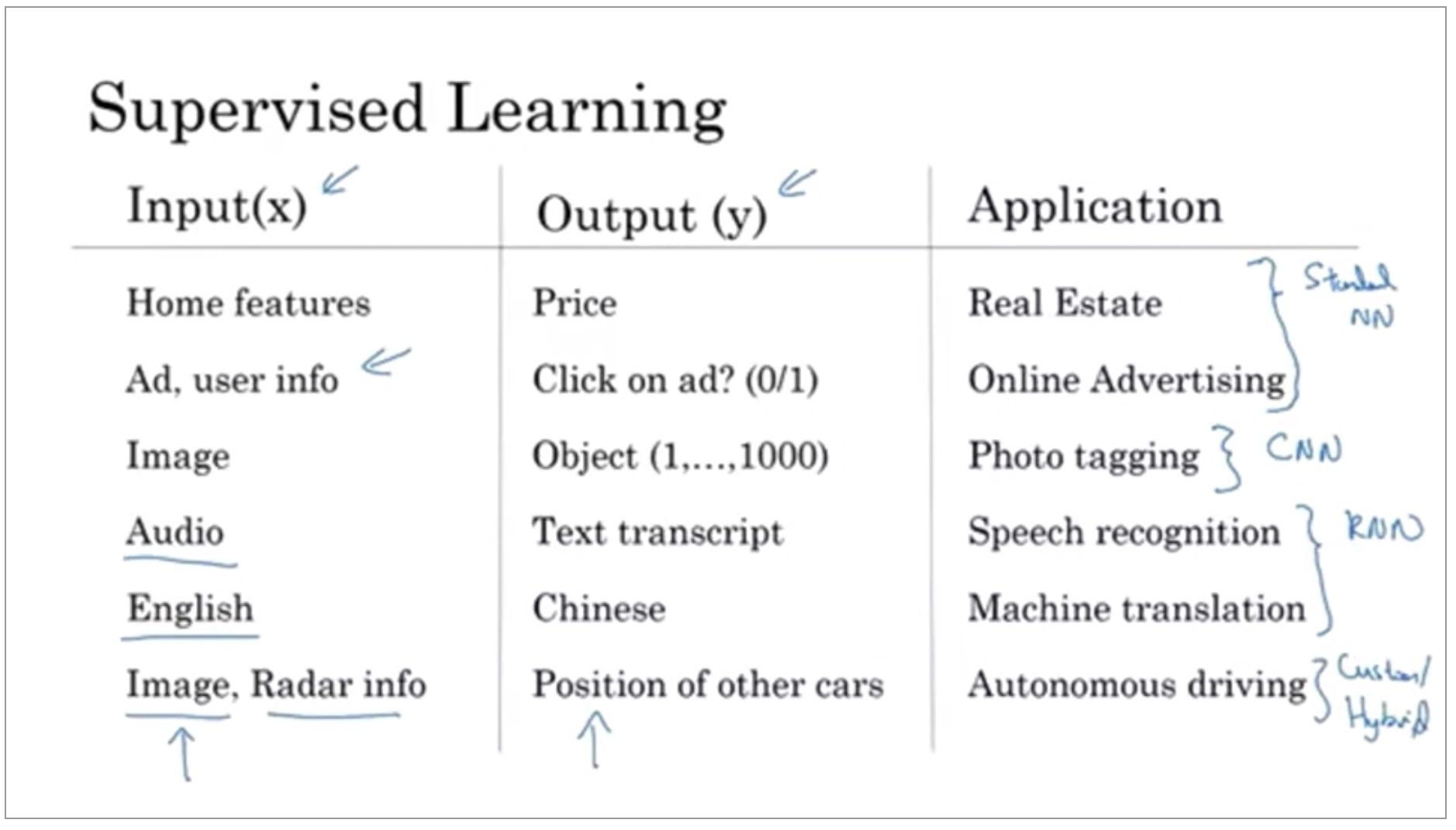
So a lot of the value creation through neural networks has been through cleverly selecting what should be x and what should be y for your particular problem, and then fitting this supervised learning component into often a bigger system such as an autonomous vehicle. It turns out that slightly different types of neural networks are useful for different applications.
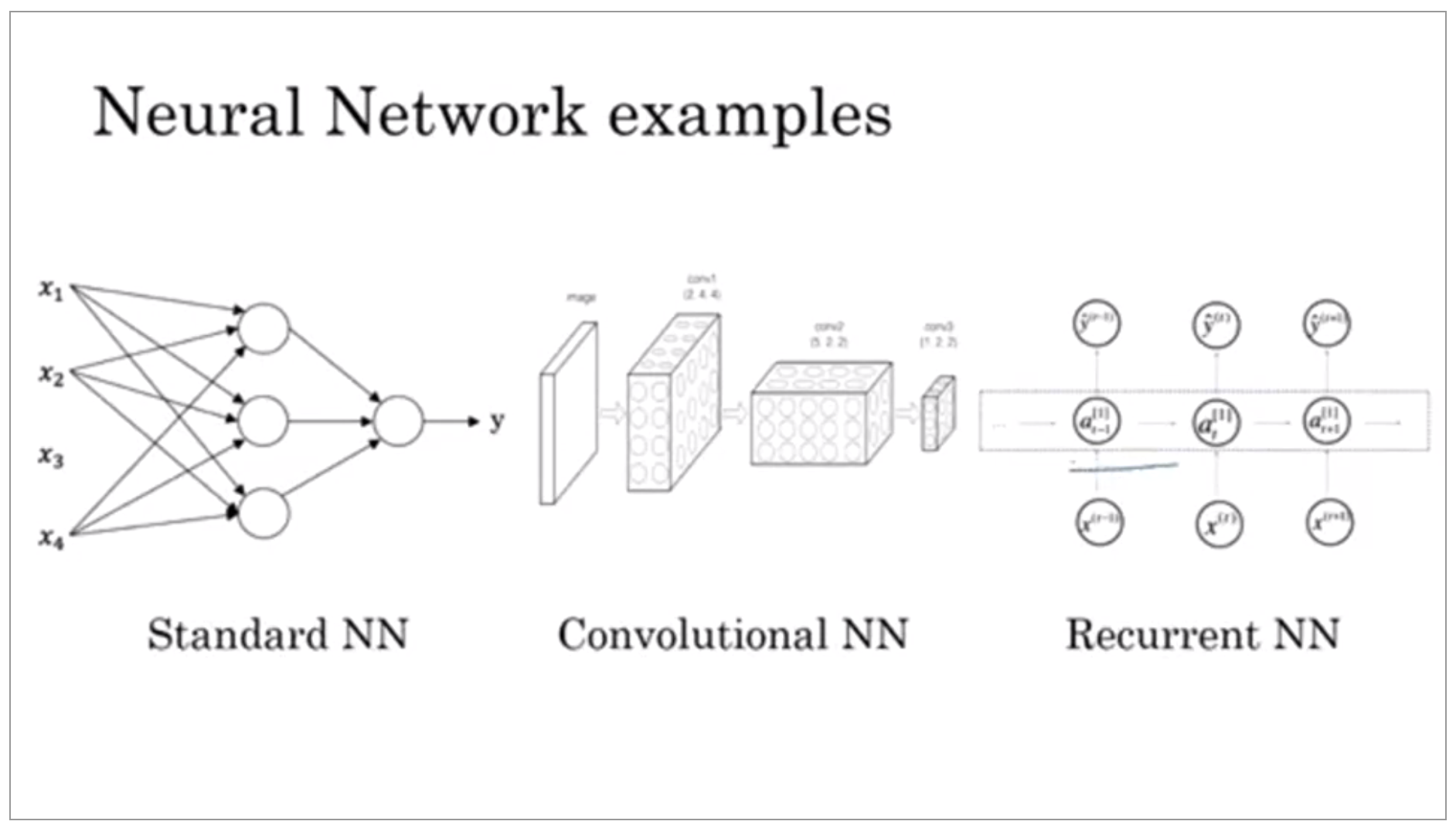
It turns out that slightly different types of neural networks are useful for different applications. For example, in the real estate application, we use a universally standard neural network architecture. For image applications we’ll often use convolution on neural networks, often abbreviated CNN. And for sequence data. So for example, audio has a temporal component, right? Audio is played out over time, so audio is most naturally represented as a one-dimensional time series or as a one-dimensional temporal sequence. And so for sequence data, you often use an RNN, a recurrent neural network.
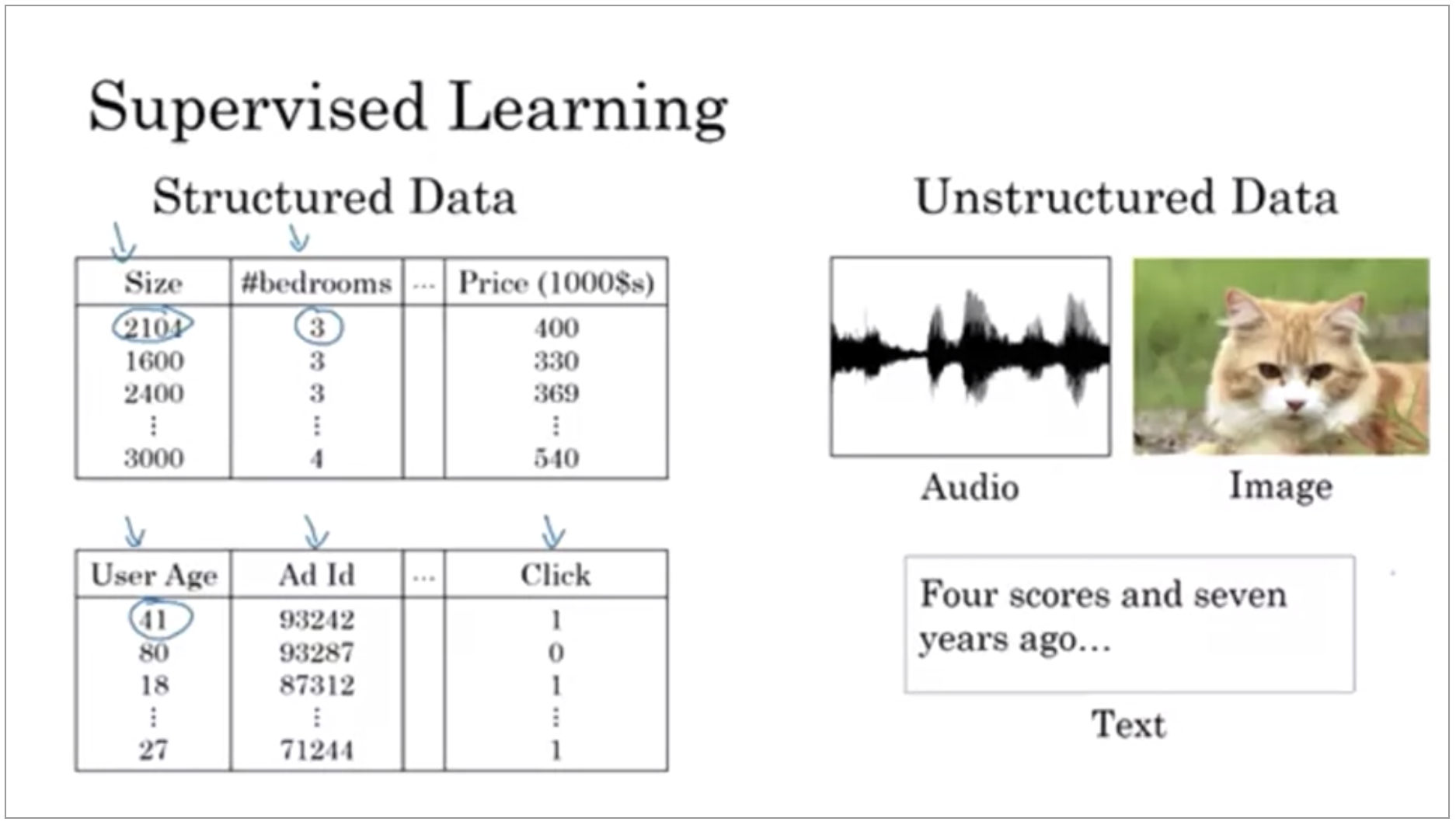
You might also have heard about applications of machine learning to both Structured Data and Unstructured Data.
Structured Data means basically databases of data. In contrast, unstructured data refers to things like audio, raw audio, or images where you might want to recognize what’s in the image or text. Here the features might be the pixel values in an image or the individual words in a piece of text. Historically, it has been much harder for computers to make sense of unstructured data compared to structured data.
And so one of the most exciting things about the rise of neural networks is that, thanks to deep learning, thanks to neural networks, computers are now much better at interpreting unstructured data as well compared to just a few years ago.
Why is Deep Learning taking off?
Why is deep learning certainly working so well?
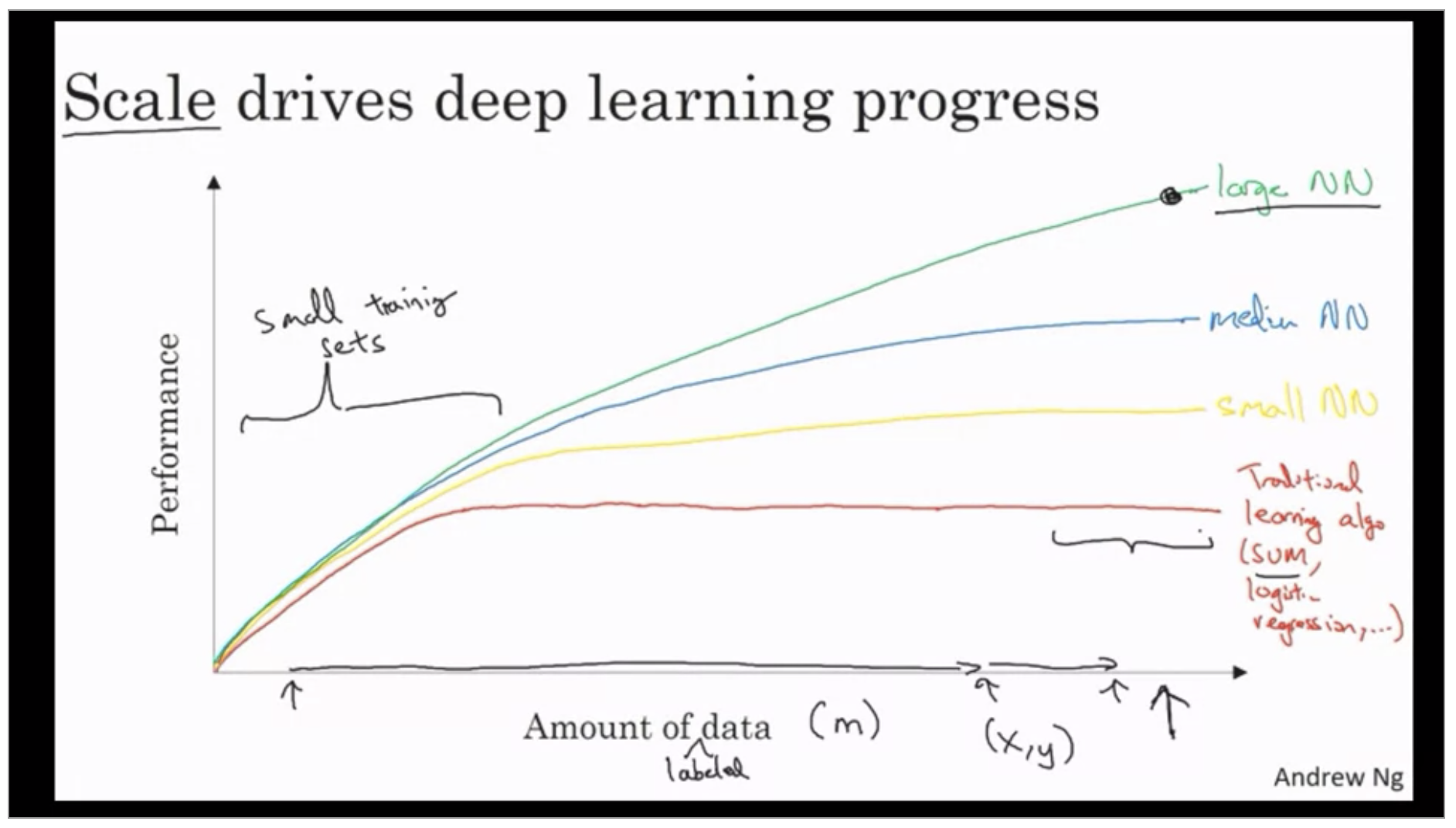
It turns out if you plot the performance of a traditional learning algorithm like support vector machine or logistic regression as a function of the amount of data you have you might get a curve that looks like this where the performance improves for a while as you add more data but after a while the performance you know pretty much plateau.
What happened in our society over the last 20 years maybe is that for a lot of problems we went from having a relatively small amount of data to having you know often a fairly large amount of data.
so couple observations one is if you want to hit this very high level of performance then you need two things. First often you need to be able to train a big enough neural network in order to take advantage of the huge amount of data. And second you need to be out here on the x axes you do need a lot of data.
If you don’t have a lot of training data is often up to your skill at hand engineering features that determines the performance. In this small training set regime the SVM could do better and Performance depends much more on your skill at engine features and other mobile details of the algorithms. In this some big data regime very large training sets very large M regime in the right that we more consistently see largely Neural Network dominating the other approaches.
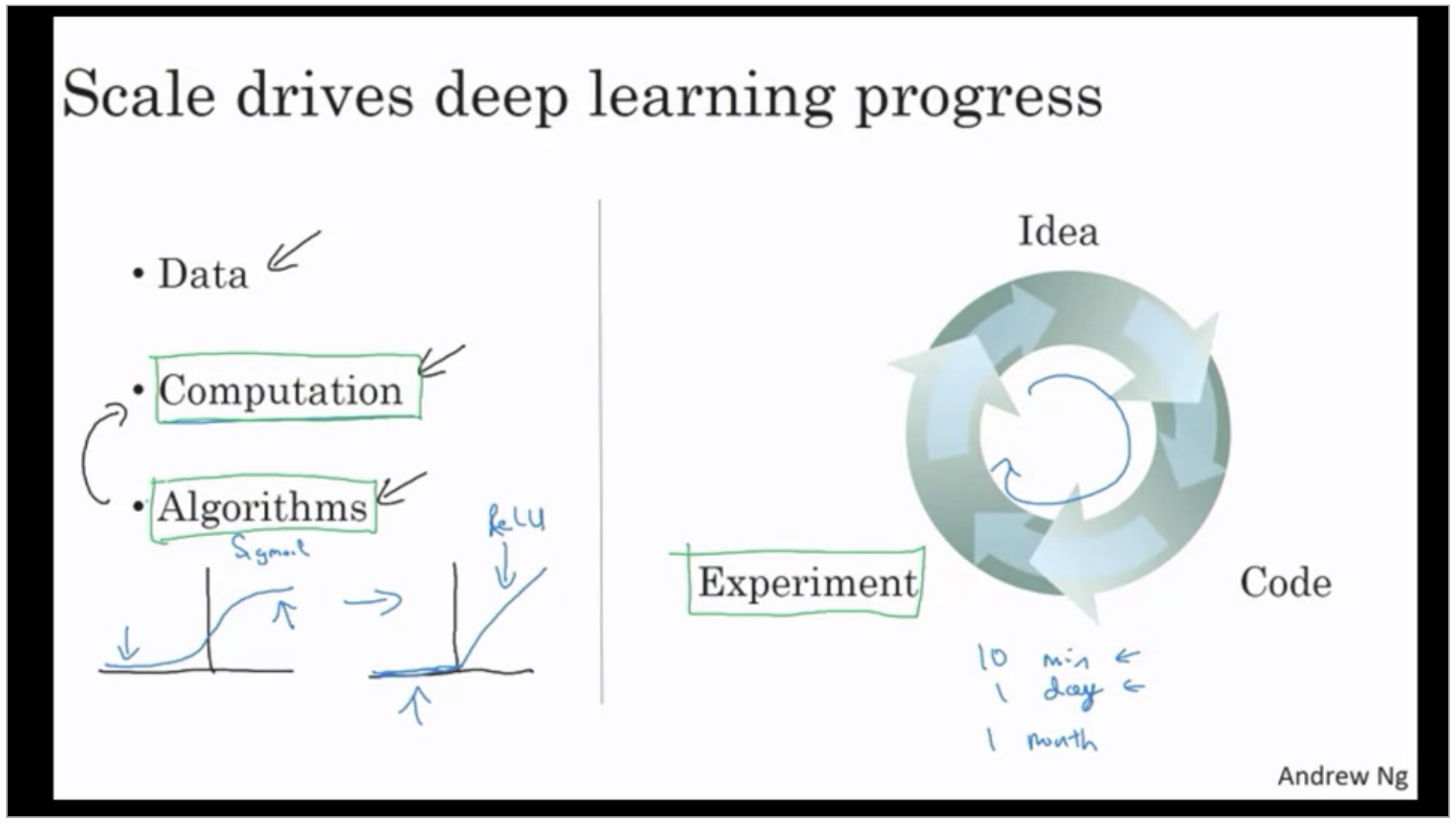
In the early days in their modern rise of deep learning it was scaled data and scale of computation just our ability to Train very large dinner networks either on a CPU or GPU that enabled us to make a lot of progress. But increasingly especially in the last several years we’ve seen tremendous algorithmic innovation. As a concrete example one of the huge breakthroughs in your networks has been switching from a sigmoid function which looks like this to a ReLU function. It turns out that one of the problems of using sigmoid functions is the slope of the function would gradient is nearly zero and so learning becomes really slow because when you implement gradient descent and gradient is zero the parameters just change very slowly and so learning is very slow. Whereas by changing the what’s called the activation function the neural network to use ReLU function. it turns out that just by switching to the sigmoid function to the ReLU function has made an algorithm called gradient descent work much faster.
The other reason that fast computation is important is that it turns out the process of training your network this is very iterative.